14.5 GraphRAG & Ontology
Consider an enterprise assistant asked: “Who is the CEO of the company that acquired the startup whose model we licensed?” A vector retriever may return chunks about the startup, the acquisition, and several CEOs, yet still miss the answer. It is strong at semantic similarity, but weak at relational traversal.
This distinction is important because many real-world questions are not simply “find a similar paragraph” problems. They are entity-and-edge problems: ownership lineage, incident timelines, dependency provenance, contract relationships, or corpus-level theme discovery. To solve those, the system must move from semantic text matching to relational reasoning. This is the domain of Knowledge Graphs (KGs) and GraphRAG.
1. When GraphRAG Is Operationally Justified
GraphRAG is operationally heavier than plain vector RAG, so it should justify its additional cost and complexity. It is most useful when the workload is dominated by:
- multi-hop questions that require following relationships across documents
- global summarization over a corpus, not just local passage lookup
- provenance-sensitive workflows where you must show how an answer was assembled
If most user traffic still looks like “find the paragraph that says X,” vector RAG is usually cheaper and simpler. GraphRAG becomes attractive when edges and communities, not just chunks, determine answer quality.
2. Ontology in the Era of LLMs
An Ontology is the formal blueprint of a knowledge graph. It defines the categories of entities (nodes) and the relationships (edges) that can exist within a specific domain.
Historically, building an ontology for the Semantic Web (using frameworks like RDF or OWL) was a grueling, human-curated process. It required strict schemas and rigid triple-stores (Subject-Predicate-Object). This brittleness made traditional knowledge graphs difficult to scale.
In the foundation model era, the paradigm has shifted to LLM-extracted Property Graphs. We no longer need armies of humans to define schemas. Instead, we use a lightweight JSON schema and prompt the LLM to dynamically extract the ontology from raw text.
- Nodes (Entities):
Person,Organization,Technology,Location. - Edges (Relationships):
FOUNDED_BY,ACQUIRED,USES_FRAMEWORK. - Properties: Metadata attached to nodes or edges (e.g.,
acquisition_date: "2024-01-15").
When an LLM processes a document, it acts as a universal parser, outputting structured graph data. This transforms unstructured text into a queryable mathematical structure.
3. Practical Implementation: Extracting Entities and Relationships
To build a Knowledge Graph from unstructured text, we prompt an LLM to identify entities and their relationships, returning them in a structured format (like JSON).
Here is a Python example using OpenAI’s structured outputs to extract graph data.
from typing import List
from pydantic import BaseModel, Field
from openai import OpenAI
client = OpenAI()
class Entity(BaseModel):
id: str = Field(description="Unique identifier for the entity, usually the name.")
type: str = Field(description="Category of entity (e.g., Person, Company, Tech)")
description: str = Field(description="Short description or role of the entity.")
class Relationship(BaseModel):
source: str = Field(description="ID of the source entity.")
target: str = Field(description="ID of the target entity.")
type: str = Field(description="Type of relationship (e.g., FOUNDED_BY, ACQUIRED_BY)")
class KnowledgeGraph(BaseModel):
entities: List[Entity]
relationships: List[Relationship]
def extract_graph(text: str) -> KnowledgeGraph:
response = client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Extract a knowledge graph from the text."},
{"role": "user", "content": text}
],
response_format=KnowledgeGraph,
)
return response.choices[0].message.parsed
text = "Elon Musk founded SpaceX in 2002. Later, SpaceX launched the Falcon 1."
graph = extract_graph(text)
print(graph.model_dump_json(indent=2))4. The Multi-Hop Traversal Problem
When a user asks a multi-hop question, the orchestrator (discussed in Chapter 14.3) must traverse the graph to retrieve the correct context.
If the query is “Who is the CEO of the company that acquired GitHub?”:
- Vector Search embeds the query and finds the node
[GitHub]. - Graph Traversal walks the edges:
[GitHub] --(ACQUIRED_BY)--> [Microsoft] --(HAS_CEO)--> [Satya Nadella]. - The LLM is fed this exact subgraph and answers correctly.
Interact with the visualizer below to see how Vector RAG misses the connection, while GraphRAG successfully traverses the relational edges.
Engineering Graph Retrieval: Random Walk with Restart (RWR)
In production, we do not manually write Cypher queries for every possible multi-hop path. Instead, graph databases use mathematical algorithms to score the relevance of surrounding nodes. A standard approach is Random Walk with Restart (RWR), a variant of PageRank.
Given a starting distribution (the initial nodes found via vector search), the algorithm simulates a random walker traversing the graph’s edges. To prevent the walker from drifting too far into irrelevant territory, it has a probability of “teleporting” back to the start.
Where is the column-normalized adjacency matrix. Below is a realistic PyTorch implementation of this retrieval mechanism.
import torch
class GraphRetriever:
"""
A PyTorch implementation of Graph Retrieval using Random Walk with Restart (RWR).
This expands an initial vector search result into a highly relevant subgraph.
"""
def __init__(self, num_nodes: int, edges: torch.Tensor, restart_prob: float = 0.15):
"""
Args:
num_nodes: Total number of entities in the knowledge graph.
edges: Tensor of shape (2, num_edges). edges[0] is source, edges[1] is target.
restart_prob: Probability (c) of teleporting back to the initial search nodes.
"""
self.num_nodes = num_nodes
self.restart_prob = restart_prob
# Initialize adjacency matrix
self.adj_matrix = torch.zeros(num_nodes, num_nodes)
# For a column-stochastic matrix where p_{t+1} = W * p_t,
# columns represent source nodes, rows represent target nodes.
self.adj_matrix[edges[1], edges[0]] = 1.0
# Normalize adjacency matrix (column-stochastic)
out_degree = self.adj_matrix.sum(dim=0, keepdim=True)
out_degree[out_degree == 0] = 1.0 # Prevent division by zero for sink nodes
self.trans_matrix = self.adj_matrix / out_degree
def retrieve_subgraph(self, initial_nodes: torch.Tensor, num_steps: int = 15) -> torch.Tensor:
"""
Args:
initial_nodes: Tensor (num_nodes, 1) representing the starting distribution
(e.g., nodes found via initial vector embedding search).
Returns:
Relevance scores for all nodes in the graph.
"""
# Normalize initial distribution
p_0 = initial_nodes / initial_nodes.sum()
p_t = p_0.clone()
# Power iteration to compute the stationary distribution
for _ in range(num_steps):
p_t = (1 - self.restart_prob) * torch.matmul(self.trans_matrix, p_t) + self.restart_prob * p_0
return p_t
# --- Example Execution ---
if __name__ == "__main__":
# Simulate a small ontology graph with 5 nodes
# e.g., 0: User Query, 1: GitHub, 2: Microsoft, 3: Satya Nadella, 4: OpenAI
edges = torch.tensor([
[1, 2, 2], # Source nodes
[2, 3, 4] # Target nodes
])
retriever = GraphRetriever(num_nodes=5, edges=edges, restart_prob=0.2)
# Simulate a vector search that highly ranks Node 1 (GitHub)
initial_dist = torch.zeros(5, 1)
initial_dist[1, 0] = 1.0
# Retrieve the multi-hop subgraph context
relevance_scores = retriever.retrieve_subgraph(initial_dist, num_steps=20)
# Select the top-k nodes to inject into the LLM context window
top_k = torch.topk(relevance_scores.squeeze(), k=3)
print(f"Top retrieved node indices: {top_k.indices.tolist()}")
print(f"Node relevance scores: {top_k.values.tolist()}")Recent graph-enhanced retrievers also push this idea further. HippoRAG, for example, combines knowledge graphs with Personalized PageRank-style retrieval to improve multi-hop recall while staying cheaper than iterative retrieval loops [3]. The broader lesson is practical: once you have an entity graph, graph search becomes another retriever in your stack, not a completely separate world.
5. Microsoft’s GraphRAG: Global Sensemaking
While traversing edges solves multi-hop questions (Local Search), it does not solve the hardest problem in RAG: Global Sensemaking.
If a user asks, “What are the main themes in this entire dataset?”, vector search fails completely. It will retrieve the top 10 chunks that semantically align with the word “theme,” missing 99% of the corpus.
In 2024, Microsoft Research introduced a novel architecture specifically named GraphRAG [1] designed to solve this global summarization problem. Rather than just using the graph for traversal at query time, Microsoft’s approach uses the graph to precompute hierarchical summaries of the entire dataset.
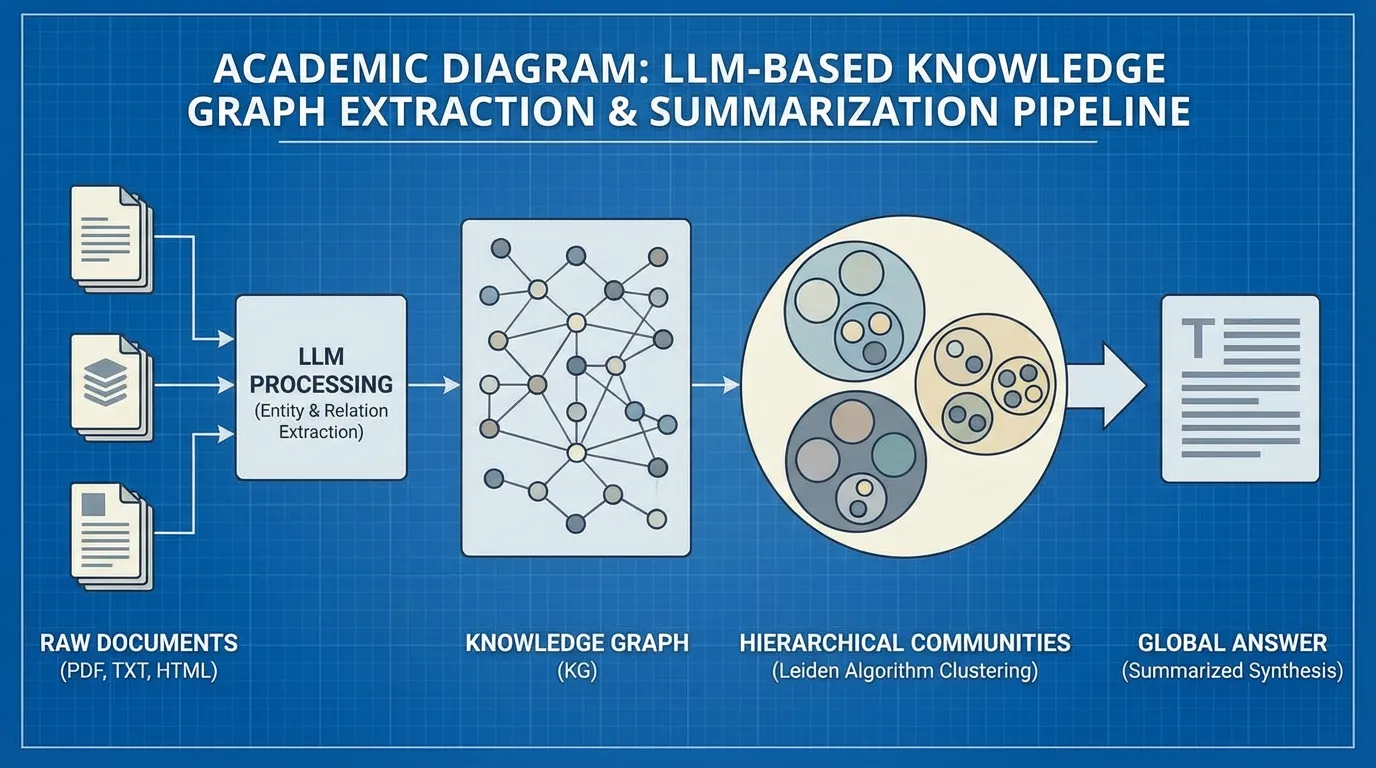
The Four Stages of Microsoft GraphRAG
- Extraction: An LLM processes all source documents, extracting entities and relationships to form a massive, unstructured knowledge graph .
- Community Detection: The system applies the Leiden algorithm [2] to partition the graph into hierarchical, well-connected clusters (communities). Entities that interact frequently (e.g., all characters and locations in a specific subplot of a book) are grouped into a community .
- Pregenerated Summarization: Before the user ever asks a question, the LLM generates a comprehensive summary for every single community in the graph.
- Map-Reduce Querying: When the global query arrives, the system does not search the raw text. Instead, it prompts the LLM to generate a partial answer using each community summary independently (Map). Finally, it rolls up all partial answers into a single, cohesive global response (Reduce).
By structuring the knowledge hierarchically, GraphRAG escapes the limitations of the context window and provides answers that accurately reflect the entirety of a million-token dataset.
6. Summary and Next Steps
GraphRAG elevates retrieval from simple text matching to relational reasoning. By structuring knowledge into ontologies and hierarchical communities, systems can dynamically traverse edges to answer multi-hop queries and perform global sensemaking over massive datasets. The practical question is not whether graphs are appealing in principle, but whether the workload truly depends on relationships, provenance, and corpus-level structure.
However, even a well-designed graph pipeline can still fail operationally. Edges can be stale, entity resolution can be wrong, re-ranking can time out, and the generator can still ignore evidence. In 14.6 RAG Failure Modes and Operational Design, we will look at how these systems break in practice and how to design for graceful degradation.
Quizzes
Quiz 1: Why does standard Vector RAG consistently fail at “Global Sensemaking” questions (e.g., “What are the main themes of the dataset?”)?
Vector RAG relies on semantic similarity to pull a small subset of top-k chunks. A global question doesn’t match any specific chunk’s embedding strongly enough to pull all relevant themes across the document. Even if it did, the context window would be flooded with disjointed text fragments rather than a cohesive summary.
Quiz 2: In the context of modern LLM-based GraphRAG, how has the concept of “Ontology” evolved compared to traditional Semantic Web architectures (RDF/OWL)?
Traditional Semantic Web required rigid, human-curated schemas (RDF/OWL) that were brittle and hard to scale. Modern GraphRAG uses LLMs to dynamically extract entities and relationships directly from unstructured text, often adhering to a flexible, lightweight schema (Property Graphs) rather than strict triple-stores.
Quiz 3: What is the specific mathematical purpose of the Leiden algorithm in Microsoft’s GraphRAG architecture?
The Leiden algorithm is used for graph community detection. It partitions the massive, unstructured entity knowledge graph into hierarchical, well-connected clusters (communities). This allows the system to generate modular summaries for closely related entities prior to query time.
Quiz 4: In the provided PyTorch Random Walk with Restart (RWR) implementation, what is the role of the
The restart_prob parameter?restart_prob (restart probability) prevents the random walk from drifting infinitely far away from the initial search results. It forces the traversal to periodically “teleport” back to the starting nodes (found via vector search), ensuring the retrieved subgraph remains heavily biased toward the user’s original query context.
Quiz 5: During graph extraction, the system may encounter contextual ambiguity where the same entity is written differently (e.g., “Musk”, “Elon”, “CEO of Tesla”). Formalize the mathematical logic used to resolve and collapse these duplicate nodes.
Entity resolution in property graphs uses a two-stage approach. First, candidate duplicates are identified via cosine similarity of node property embeddings: . Second, confirmed pairs are collapsed by merging their edge adjacency allocations: . This prevents isolated ambiguity from bifurcating traversal paths during multi-hop RWR steps.
References
- Edge, D., et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130.
- Traag, V. A., Waltman, L., & van Eck, N. J. (2019). From Louvain to Leiden: guaranteeing well-connected communities. Scientific Reports.
- Gutiérrez, B. J., Shu, Y., Gu, Y., Yasunaga, M., & Su, Y. (2025). HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv:2405.14831.