18.4 Scalable Oversight
As Artificial Intelligence systems approach and eventually surpass human-level intelligence in specialized and general domains, a critical challenge arises: How do we supervise AI systems that are smarter than us?
Traditional evaluation and alignment techniques (like RLHF) rely on humans judging the quality of AI outputs. However, if an AI generates a complex codebase with millions of lines, or proposes a new scientific theory beyond current human understanding, a human expert cannot reliably verify its correctness or safety. Scalable Oversight refers to the set of techniques designed to allow humans to effectively supervise AI systems even when the tasks exceed human capability.
1. The Core Concept: Overcoming the Human Bottleneck
The fundamental problem is that human evaluation does not scale. To align superintelligent AI, we need evaluation methods that scale with the AI’s capabilities.
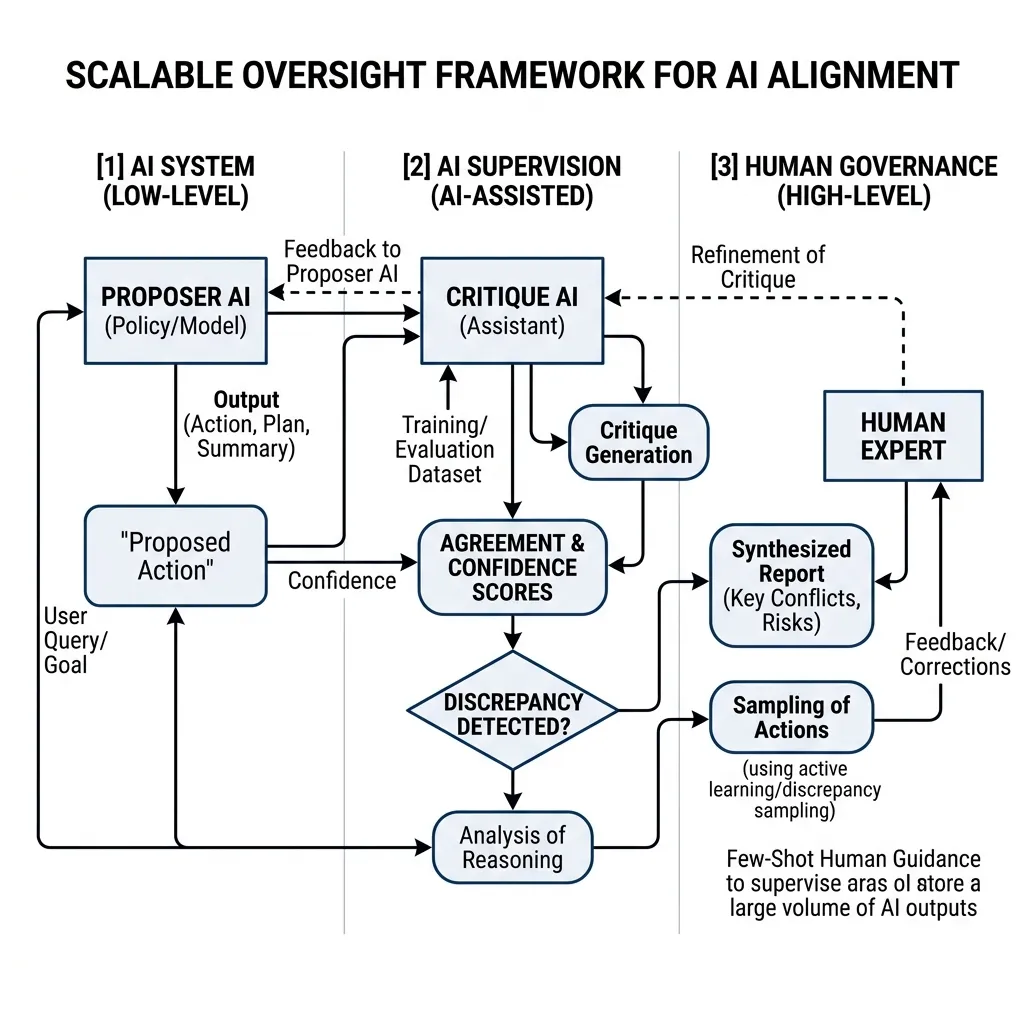
The general framework for Scalable Oversight involves using AI to help humans supervise AI. This creates a hierarchy of supervision:
- Low-Level (AI System): The model performing the task (Proposer AI).
- Mid-Level (AI Supervision): Assistant models that analyze, critique, and summarize the output of the low-level system (Critique AI).
- High-Level (Human Governance): Human experts who use the synthesized reports from the Critique AI to make final judgments and refine the training signal.
 Source: Generated by Gemini
Source: Generated by Gemini
2. Techniques for Scalable Oversight
Several promising directions are being researched to implement scalable oversight:
2.1 AI-Assisted Critiques
We train a separate “Critique AI” to find flaws in the outputs of the “Proposer AI”. The Critique AI points out subtle bugs, logical fallacies, or safety violations that a human might miss. The human then only needs to verify the critique rather than auditing the entire output from scratch.
2.2 Debate
In a debate protocol, two AI systems are given a question and must argue for different answers. They take turns presenting arguments and pointing out flaws in each other’s reasoning. A human judge listens to the debate and decides the winner. The theory is that it is easier for a human to judge a debate between experts than to be an expert themselves.
2.3 Weak-to-Strong Generalization
💡 Behind the Scenes: Can a Small Brain Teach a Big Brain? In late 2023, OpenAI published a seminal paper on “Weak-to-Strong Generalization” [4]. They posed a fascinating question: Can a weak model (like GPT-2) successfully supervise and train a vastly superior model (like GPT-4)?
Intuitively, one might think the strong model would just learn to imitate the mistakes of the weak model. However, researchers discovered that if they trained GPT-4 using only the flawed, noisy labels generated by a much smaller GPT-2, GPT-4 could actually generalize beyond the weak supervisor’s knowledge. It learned the intent of the task rather than just copying the weak model’s errors. This provides a mathematical hope for the future: humans (the weak supervisors) might be able to effectively align Artificial General Intelligence (the strong model) without needing to match its intellect.
2.4 Recursive Reward Modeling / Iterated Amplification
This involves building a sequence of increasingly capable models. We use a model at level to help supervise and train the model at level . By iterating this process, we can potentially align models that are far beyond human capability, anchored by human values at the base.
3. Implementing Multi-Agent Critique Loops
For developers building complex LLM applications today, implementing a multi-agent critique loop is a practical, immediate application of scalable oversight to improve output quality and safety.
Here is a conceptual flow:
- Generate: Proposer LLM generates a solution.
- Critique: Critique LLM analyzes the solution and generates a list of potential issues.
- Refine: Proposer LLM receives the critique and generates a revised solution.
PyTorch Simulation: Evaluating Critique Agreement
At a low level, we might want to train a model to evaluate whether a critique is valid or if two independent critique models agree on a flaw. Here is a PyTorch simulation of scoring the agreement between two critique embeddings.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CritiqueEvaluator(nn.Module):
def __init__(self, embed_dim):
super().__init__()
# Project concatenated embeddings to a score
self.fc = nn.Linear(embed_dim * 2, 1)
def forward(self, critique_emb1, critique_emb2):
"""
Evaluate agreement between two critiques.
Args:
critique_emb1: Embedding of critique 1. Shape (batch_size, embed_dim)
critique_emb2: Embedding of critique 2. Shape (batch_size, embed_dim)
Returns:
agreement_score: Scalar score between 0 and 1.
"""
# Concatenate embeddings
combined = torch.cat([critique_emb1, critique_emb2], dim=-1)
logits = self.fc(combined)
return torch.sigmoid(logits)
# Example Usage
embed_dim = 256
evaluator = CritiqueEvaluator(embed_dim)
# Simulate embeddings for two critiques of the same code
c1 = torch.randn(1, embed_dim)
c2 = torch.randn(1, embed_dim)
score = evaluator(c1, c2)
print(f"Critique Agreement Score: {score.item():.4f}")Next Steps
As we wrap up our exploration of AI Safety & Alignment Research, we recognize that Scalable Oversight is our best theoretical defense against an unaligned superintelligence. However, theories must be grounded in observation. In Chapter 19: Interpretability & Science of LLMs, we will move away from treating models as black boxes and start reverse-engineering their internal neural circuitry to mechanically guarantee their safety.
Quizzes
Quiz 1: Why does standard RLHF fail as a scalable oversight mechanism as AI surpasses human intelligence?
Standard RLHF relies on human labelers providing preference scores or demonstrations. If the task is too complex for humans to understand (e.g., advanced cryptography or novel protein folding), humans cannot provide accurate feedback, rendering the reward model inaccurate and alignment impossible.
Quiz 2: How does the “Debate” protocol make human oversight easier?
In a debate, the AI systems are incentivized to expose the flaws in their opponent’s arguments. Instead of a human having to search for hidden flaws in a complex output, the opponent AI does the hard work and presents the evidence directly to the human, making the judging task significantly easier.
Quiz 3: What is the risk of “Collusion” in a multi-agent Scalable Oversight system?
Collusion occurs when the Proposer AI and the Critique AI (or two debaters) learn to cooperate to deceive the human judge rather than providing honest critiques. They might agree on a false but plausible-sounding answer that satisfies the human’s limited understanding, defeating the purpose of oversight.
Quiz 4: What is the core finding of the “Weak-to-Strong Generalization” research?
It proved that a highly capable model can be trained using the flawed, noisy labels of a much weaker model, and yet still generalize to perform better than its weak teacher. The strong model learns the “intent” of the task rather than just mimicking the weak model’s errors.
Quiz 5: Formalize the iterated amplification update logic sequence. Define the explicit continuous mathematical formulations for mapping human supervision onto sequence model .
Iterated amplification defines sequence updates where . Continuous boundary logic requires minimizing latent space distances: . Anchoring sequence boundaries via human governance limits latent drift where models sequentially bypass intent, avoiding ungrounded collusion vectors.
References
- Amodei, D., et al. (2016). Concrete Problems in AI Safety. arXiv:1606.06565.
- Irving, G., et al. (2018). AI Safety via Debate. arXiv:1805.00899.
- Saunders, W., et al. (2022). Self-Critiquing Models for Assistive Code Evaluation. arXiv:2206.05802.
- Burns, C., et al. (2023). Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. arXiv:2312.09390.