7.2 ZeRO (Zero Redundancy Optimizer)
In the previous section, we established that Distributed Data Parallel (DDP) scales compute linearly by slicing the dataset across multiple GPUs. However, DDP harbors a fatal physical limitation: every GPU in the cluster must hold a complete, identical replica of the model and its training states.
As Foundation Models grew from 1 billion parameters in 2019 to over 100 billion parameters by 2020, engineers slammed into a physical barrier known as the Memory Wall. No matter how many GPUs you added to your cluster, if the model could not fit into the VRAM of a single GPU, training was impossible.
To break this barrier, researchers at Microsoft developed the Zero Redundancy Optimizer (ZeRO) [1]. ZeRO fundamentally reimagines distributed training by treating the entire cluster’s VRAM as a single, contiguous memory pool. It provides the memory efficiency of Model Parallelism while maintaining the simplicity and communication efficiency of Data Parallelism.
1. The Anatomy of GPU Memory
To understand how ZeRO optimizes memory, we must first dissect where the memory goes during training.
During mixed-precision training (which is standard for Foundation Models), GPU memory is consumed by two main categories: Residual States (activations, temporary buffers, fragmentation) and Model States.
Model States are the primary bottleneck. Let be the total number of parameters in the model. If we use mixed-precision training (FP16/BF16) with the Adam optimizer, the memory footprint per GPU under standard DDP is:
- Parameters (FP16): bytes.
- Gradients (FP16): bytes.
- Optimizer States (FP32): Adam requires storing an FP32 copy of the master weights, the momentum (1st moment), and the variance (2nd moment).
- Master Weights: bytes
- Momentum: bytes
- Variance: bytes
- Total Optimizer State: bytes.
Total Model State Memory = bytes.
Notice a striking reality: The optimizer states consume 75% of the memory ( out of ).
If we attempt to train a 70-billion parameter model (like Llama 3 70B), the Model States alone require of VRAM. An NVIDIA H100 GPU has 80GB of VRAM. Under standard DDP, this model is mathematically impossible to train, regardless of whether you have 1 GPU or 10,000 GPUs.
2. The ZeRO Philosophy: Data Parallelism on Steroids
Standard DDP uses an All-Reduce operation to average gradients. After the backward pass, every GPU has the exact same gradients, and every GPU independently performs the exact same optimizer step to update its identical replica of the weights. This is massive redundancy.
ZeRO eliminates this redundancy by partitioning the model states across the GPUs in the cluster, rather than replicating them. ZeRO is implemented in three progressive stages.
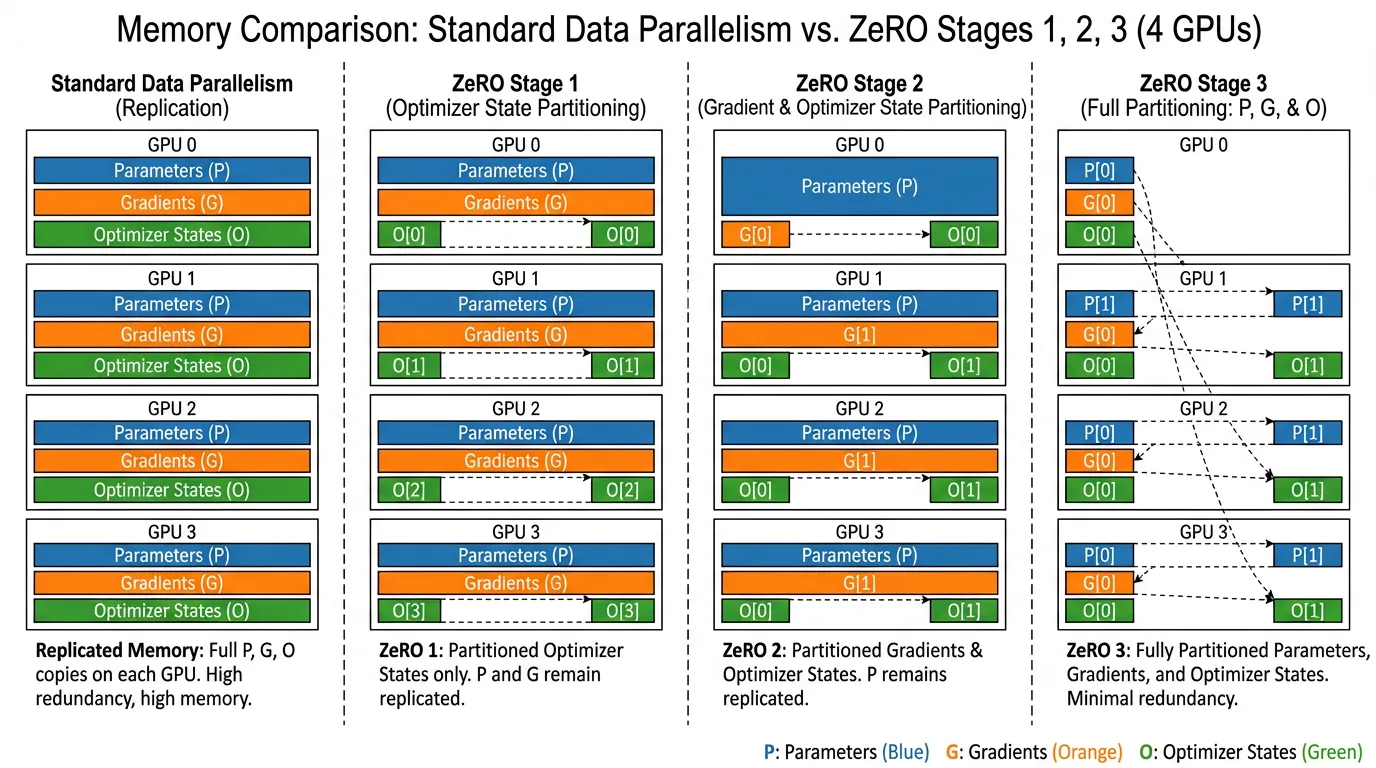 Source: Generated by Gemini. Inspired by Rajbhandari et al., 2020.
Source: Generated by Gemini. Inspired by Rajbhandari et al., 2020.
Stage 1: Optimizer State Partitioning ()
Instead of every GPU storing the massive optimizer states, ZeRO-1 slices the optimizer states into equal partitions.
- GPU only stores the optimizer states for its specific partition of the parameters.
- GPU is solely responsible for updating its assigned slice of the weights.
- Memory Footprint: Drops from to .
- Communication Overhead: 0%. Instead of an All-Reduce, ZeRO uses a Reduce-Scatter for gradients, followed by an All-Gather for the updated weights. The total data transmitted over the network is mathematically identical to standard DDP’s All-Reduce.
Stage 2: Gradient Partitioning ()
If GPU is only responsible for updating partition of the weights, it does not need to store the entire gradient tensor. In ZeRO-2, as soon as a gradient bucket is computed during the backward pass, it is immediately reduced and scattered to the responsible GPU, and then the local replica is discarded.
- Memory Footprint: Drops to .
- Communication Overhead: 0%. It uses the exact same Reduce-Scatter/All-Gather primitive as Stage 1.
Stage 3: Parameter Partitioning ()
This is the holy grail, often referred to as Fully Sharded Data Parallel (FSDP) in the PyTorch ecosystem. ZeRO-3 partitions the parameters themselves. The GPUs hold no complete model.
- Mechanism: When a specific transformer layer needs to compute its forward or backward pass, ZeRO-3 performs a Just-In-Time (JIT) All-Gather to reconstruct that specific layer’s weights. As soon as the computation for that layer is finished, the weights are instantly discarded from memory.
- Memory Footprint: Scales linearly with the cluster size: .
- Communication Overhead: ~1.5x. Because weights must be All-Gathered during both the forward and backward passes, the network volume increases by 50% compared to DDP. However, this is easily hidden by overlapping the communication of Layer with the computation of Layer .
3. Interactive Visualization: The Memory Wall
Use the interactive component below to simulate the memory footprint of different Foundation Models across varying cluster sizes. Notice how standard DDP quickly exceeds the 80GB VRAM limit of an H100, while ZeRO-3 keeps the memory footprint comfortably low, allowing the remaining VRAM to be used for larger batch sizes or longer context windows.
ZeRO Memory Footprint Simulator
Analyze Model State Memory per GPU (FP16/BF16 + Adam)
(Note: The visualizer calculates pure Model State memory. In practice, you must also account for activation memory, which can be mitigated using Activation Checkpointing.)
4. Beyond GPU Limits: ZeRO-Offload & ZeRO-Infinity
While ZeRO-3 allows memory to scale linearly with the number of GPUs, what if you are a researcher with only a single GPU or a small 4-GPU node?
The DeepSpeed team introduced ZeRO-Offload [2] and ZeRO-Infinity [3] to exploit the entire system’s memory hierarchy.
- ZeRO-Offload (CPU RAM): The CPU is computationally slow but has massive memory (often 1TB+ of system RAM). ZeRO-Offload moves the Optimizer States and the Adam computation to the CPU. While the GPU computes the forward/backward pass for step , the CPU asynchronously updates the weights for step and transfers them back via PCIe. This allows training a 13-billion parameter model on a single GPU.
- ZeRO-Infinity (NVMe Storage): Extending the offload concept to NVMe Solid State Drives. By treating high-speed NVMe storage as a massive virtual memory pool and using memory-centric tiling, ZeRO-Infinity allows a single machine to host and fine-tune models with trillions of parameters, completely shattering the GPU memory barrier.
5. Engineering Implementation (DeepSpeed)
Writing the low-level Reduce-Scatter and All-Gather CUDA kernels for ZeRO is incredibly complex. Today, engineers rely on Microsoft’s deepspeed library or PyTorch’s native FSDP.
Below is a production-grade example of integrating ZeRO-3 using DeepSpeed. Notice how DeepSpeed acts as a wrapper around standard PyTorch code.
The DeepSpeed Configuration (ds_config.json)
DeepSpeed is driven by a JSON configuration file. This dictates the ZeRO stage and offloading behavior without requiring changes to the model architecture.
{
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 2e-5,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": 5e7,
"stage3_prefetch_bucket_size": 5e7,
"stage3_param_persistence_threshold": 1e5,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
}
}
}The PyTorch Integration Script
import torch
import torch.nn as nn
import deepspeed
from torch.utils.data import DataLoader, Dataset
# 1. Define a standard PyTorch Model
# Even if this model is 50B parameters and cannot fit on one GPU,
# DeepSpeed will partition it automatically during initialization.
class SimpleLLM(nn.Module):
def __init__(self, vocab_size=32000, d_model=4096):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
# In reality, this would be a stack of Transformer blocks
self.layers = nn.Sequential(
*[nn.Linear(d_model, d_model) for _ in range(24)]
)
self.lm_head = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embed(x)
x = self.layers(x)
return self.lm_head(x)
# Dummy Dataset
class DummyDataset(Dataset):
def __len__(self): return 1000
def __getitem__(self, idx):
return torch.randint(0, 32000, (512,)), torch.randint(0, 32000, (512,))
def train():
# 2. Initialize DeepSpeed Distributed Backend
deepspeed.init_distributed()
model = SimpleLLM()
dataset = DummyDataset()
# 3. Initialize DeepSpeed Engine
# DeepSpeed replaces the standard PyTorch DDP wrapper and Optimizer
model_engine, optimizer, _, dataloader = deepspeed.initialize(
args=None,
model=model,
model_parameters=model.parameters(),
training_data=dataset,
config="ds_config.json"
)
criterion = nn.CrossEntropyLoss()
# 4. Training Loop
for epoch in range(3):
for step, (inputs, targets) in enumerate(dataloader):
# Move data to the local GPU
inputs = inputs.to(model_engine.local_rank)
targets = targets.to(model_engine.local_rank)
# Forward pass (ZeRO-3 automatically All-Gathers weights layer-by-layer)
outputs = model_engine(inputs)
loss = criterion(outputs.view(-1, 32000), targets.view(-1))
# Backward pass (ZeRO-3 automatically Reduce-Scatters gradients)
model_engine.backward(loss)
# Optimizer step
model_engine.step()
if model_engine.local_rank == 0 and step % 10 == 0:
print(f"Epoch {epoch} | Step {step} | Loss {loss.item():.4f}")
if __name__ == "__main__":
# Execution requires the deepspeed launcher to handle process spawning
# deepspeed --num_gpus=8 train_zero.py
train()The Engineering Trade-off
While ZeRO-3 is magical, it is not a silver bullet. The Just-In-Time broadcasting of weights makes training highly sensitive to network bandwidth. If your cluster lacks high-speed InfiniBand or NVLink, the GPUs will stall waiting for weights to arrive over the network. In such cases, engineers often fall back to ZeRO-2, or combine ZeRO-1 with Tensor Parallelism (which we will explore in Chapter 7.3).
Summary
ZeRO transformed distributed training from a hardware-bound limitation into a software-defined scaling problem. By recognizing that standard Data Parallelism wastes VRAM by replicating identical states, ZeRO partitions the Optimizer States (Stage 1), Gradients (Stage 2), and Parameters (Stage 3).
Coupled with CPU and NVMe offloading, ZeRO democratized the training of Foundation Models, allowing massive models to be trained on relatively modest hardware. However, as models push past 500 billion parameters, even ZeRO-3 across thousands of GPUs begins to experience network congestion. To solve this, we must physically slice the matrix multiplications themselves. In the next section, we will dive into 7.3 Model & Pipeline Parallelism.
Quizzes
Quiz 1: Why does ZeRO Stage 1 and Stage 2 introduce zero additional communication overhead compared to standard Distributed Data Parallel (DDP)?
Standard DDP uses an All-Reduce operation, which is mathematically equivalent to a Reduce-Scatter followed by an All-Gather. In DDP, the All-Reduce synchronizes the gradients. In ZeRO-1/2, the framework performs a Reduce-Scatter on the gradients (so each GPU gets its partitioned slice), each GPU updates its specific slice of the weights, and then performs an All-Gather to broadcast the updated weights. The total network volume transmitted remains exactly the same as the original All-Reduce.
Quiz 2: If ZeRO-3 partitions the parameters, how does a GPU compute the forward pass for a specific transformer layer if it only holds a fraction of that layer’s weights?
ZeRO-3 uses a Just-In-Time (JIT) parameter reconstruction mechanism. Right before a layer is executed, the framework triggers an All-Gather operation to pull the missing weight shards from all other GPUs. Once the layer’s forward (or backward) computation is complete, the reconstructed weights are immediately deleted from the GPU’s memory to free up space.
Quiz 3: You are training a 10B parameter model using ZeRO-Offload. You notice that GPU utilization (MFU) has dropped significantly, and the GPU is frequently idle. What is the most likely system bottleneck?
The PCIe bandwidth or the CPU compute speed. ZeRO-Offload moves the optimizer step to the CPU. If the CPU is too slow at computing the Adam updates, or if the PCIe bus is too slow to transfer the updated weights back to the GPU in time for the next forward pass, the GPU will stall and wait for the CPU, drastically lowering utilization.
Quiz 4: In mixed precision training (FP16/FP32), why do the optimizer states consume significantly more memory than the model parameters themselves?
The parameters are stored in 16-bit floating point (FP16/BF16), taking 2 bytes per parameter. However, optimizers like Adam require high precision to prevent numerical underflow during small gradient updates. Therefore, Adam maintains an FP32 (4 bytes) copy of the master weights, an FP32 momentum tensor, and an FP32 variance tensor. This totals 12 bytes per parameter, which is 6x larger than the original FP16 weights.
References
- Rajbhandari, S., et al. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. SC20. arXiv:1910.02054.
- Ren, J., et al. (2021). ZeRO-Offload: Democratizing Billion-Scale Model Training. USENIX ATC. arXiv:2101.06840.
- Rajbhandari, S., et al. (2021). ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. SC21. arXiv:2104.07857.