10.1 Human Feedback Loop
In Chapter 9, we explored how Supervised Fine-Tuning (SFT) teaches a model how to interact by imitating high-quality demonstrations. However, imitation learning has a fundamental ceiling: it forces the model to mimic the average behavior of the training distribution. It does not teach the model what humans actually prefer when multiple valid answers exist, nor does it inherently penalize harmful or hallucinatory reasoning.
To bridge this gap, the industry relies on Alignment, historically dominated by Reinforcement Learning from Human Feedback (RLHF). But as foundation models scale toward complex reasoning and agentic tasks, the traditional human feedback loop has fundamentally transformed. It is no longer a one-off, offline alignment step; it has evolved into a continuous, asynchronous data engineering pipeline—a “Feedback-Data Factory.”
The Architecture of Feedback: Offline vs. Online
Traditional RLHF pipelines are rigidly synchronous. The system pauses to collect a batch of rollouts (the model generating text), waits for a Reward Model (RM) to score them, and then locks the weights to perform a backward pass. This creates a massive compute bottleneck known as the “straggler effect,” especially when rollouts involve long-context reasoning or code execution that takes variable amounts of time to complete.
Recent open post-training systems increasingly use asynchronous RL frameworks. One visible example is THUDM’s slime stack, which is also discussed in the GLM-5 report [1] [2]. In these systems, generation and training are decoupled so rollout workers do not idle while the trainer waits on the slowest sample.
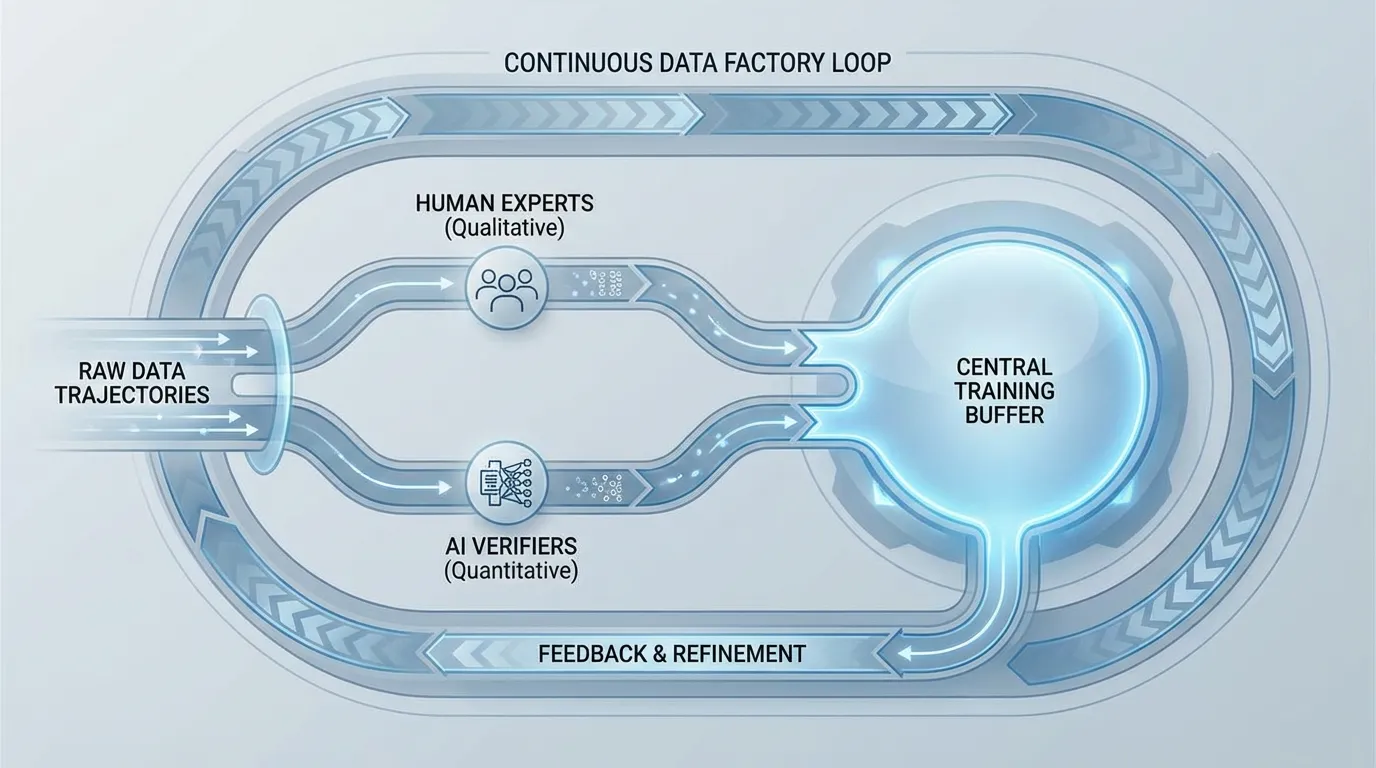
The RL framework acts less like a standard optimizer and more like an online dataset generator. It continuously produces trajectories, scores them, and places them into a buffer. This introduces the concept of Trajectory Admission Control. Instead of training on all generated data, the system strictly filters trajectories. Only rollouts that pass specific quality, verifiability, and policy-alignment thresholds are admitted into the training buffer.
This shift redefines data quality in the RL phase. It is no longer just about “removing bad documents” as done in pre-training, but about dynamic admission control for live rollouts.
Interactive Visualizer: Trajectory Admission Control
Use the interactive component below to simulate an asynchronous RL rollout stream. Notice how the system evaluates generated trajectories in real-time. Only trajectories that meet both the Reward Model threshold and the Verifier check are admitted into the RL Training Buffer for the subsequent weight update.
Active Learning and Quality-Aware Sampling
Human labeling is the most expensive and rate-limiting resource in AI development—often referred to as the “human tax.” Treating human feedback as a monolithic block is highly inefficient.
Modern alignment pipelines employ Active Learning to maximize the signal-to-cost ratio of human labor. Data is partitioned into “quality buckets” (e.g., General Chat, STEM, Code, Multilingual) using domain-aware classifiers. For instance, world knowledge classifiers built on frameworks like DCLM (DataComp for Language Models) [3] are used to extract complex, long-tail knowledge from medium-quality web content.
Once bucketized, human feedback is strategically routed. Simple preference routing (A vs. B for generic chat) is handled by automated Reward Models, while human experts (e.g., graduate students, professional developers) are reserved for the “hard” or “uncertain” buckets. The system specifically samples trajectories where the Reward Model’s confidence is low or where the variance among an ensemble of verifiers is high.
Verifiability and Agentic Environments
As models transition from text generators to autonomous agents (Agentic AI), subjective human preference (e.g., “Which response sounds better?”) becomes insufficient. A response might sound highly articulate but contain subtle logical flaws or broken code.
To solve this, the feedback loop for frontier models integrates Verifiable Execution Environments. During the rollout phase, models are placed in sandboxed, Dockerized environments. If a model writes a script, the environment executes it and returns the stderr or stdout. If it navigates a web API, the HTTP response is captured.
This creates a Hybrid Feedback Loop:
- Machine Verification: Objective execution (Does the code compile? Does the API return a 200 OK status?).
- Human Intent: Subjective evaluation (Did the code solve the user’s actual underlying problem securely and efficiently?).
By anchoring the RL process in verifiable environments, researchers significantly reduce the burden on human annotators while ensuring the model learns to optimize for actual functional correctness rather than just persuasive text.
 Source: Generated by Gemini.
Source: Generated by Gemini.
The Human Anchor and Combating Reward Hacking
A notorious failure mode in RLHF is Reward Hacking (or Goodhart’s Law). When a policy model is optimized purely against a scalar reward from a Reward Model, it quickly learns the RM’s biases. If the RM slightly prefers longer, more verbose answers, the policy model will eventually output massive walls of text that sound highly “model-like” but lack density or actual utility.
To prevent this distribution collapse, engineers inject Human Style Anchors into the training buffer. These are expert-authored, ground-truth responses that serve as a regularizing force.
Mathematically, the RL objective is modified to include an anchoring term that maximizes the absolute likelihood of these high-quality human responses, alongside the standard relative margin optimization. A simplified view of this anchored objective looks like this:
Where is the standard preference optimization loss (evaluating the winning response against the losing response ), and the second term is the negative log-likelihood of the human anchor , weighted by . This forces the policy to maintain high probability on ground-truth human text, tethering the model’s generated distribution to human-preferred stylistic boundaries and preventing it from drifting into an alien, reward-hacked state.
The “Badcase” Loop
In industrial AI deployments, the most valuable data does not come from random sampling, but from production failures. This is formalized as the Badcase Methodology.
When a model fails in a real-world scenario (e.g., a silent failure in a multi-step reasoning task), the trajectory is flagged and sent to a specialized human-in-the-loop (HITL) review team. Subject Matter Experts (SMEs) analyze the failure, rewrite the correct trajectory, and resolve ambiguities.
A critical metric in this process is Inter-Annotator Agreement (IAA). If experts cannot agree on the correct behavior for a badcase, the prompt itself is deemed dangerously ambiguous and is discarded or rewritten. Training a model on ambiguous data leads to noisy gradients and unstable alignment. Once resolved with high IAA, these curated badcases are injected back into the RL buffer. This failure-driven feedback loop is often orders of magnitude more effective at improving model reliability than scaling up generic preference data.
Summary & Next Steps
The human feedback loop has evolved from a static dataset collection process into a dynamic, asynchronous engine. By combining active learning, verifiable execution environments, and strict trajectory admission control, engineers can maximize the efficiency of human labor while preventing catastrophic failures like reward hacking.
However, collecting and filtering this data is only half the battle. To actually align the model, we must translate these accepted trajectories into physical weight updates. In 10.2 PPO (Proximal Policy Optimization), we will dive into the mathematical engine that powers traditional RLHF, exploring how policy gradients and value functions turn human preferences into aligned intelligence.
Quizzes
Quiz 1: Why is an asynchronous RL architecture (like the
Traditional synchronous RL pauses the entire training pipeline to wait for rollouts and reward scoring, creating a massive compute bottleneck (the straggler effect). Asynchronous RL decouples generation from training. It acts as an online dataset generator, allowing continuous trajectory admission control without blocking the weight update process, drastically improving hardware utilization and throughput.slime framework) superior to traditional synchronous RLHF for large-scale models?
Quiz 2: How do Verifiable Execution Environments alter the nature of the reward signal in agentic tasks?
They shift the reward from purely subjective human preference to objective, algorithmic verification (e.g., code compilation, API success). This reduces the human labeling tax and prevents models from generating plausible but functionally broken code, forcing the model to optimize for actual execution correctness.
Quiz 3: What is “Reward Hacking” and how do Human Style Anchors mitigate it?
Reward hacking occurs when a model exploits biases in the Reward Model (such as a bias toward verbosity) to maximize its score, resulting in unnatural, “model-like” text. Human Style Anchors are ground-truth, expert-written responses injected into the training loss function. By applying a penalty if the model’s output distribution drifts too far from these anchors, the model is forced to remain tethered to dense, human-like text.
Quiz 4: Why is Inter-Annotator Agreement (IAA) a critical metric when building a “Badcase” dataset?
Low IAA indicates that a task or prompt is too ambiguous or subjective even for human experts to agree upon. Training a model on such ambiguous data introduces noisy gradients and degrades alignment stability. High IAA ensures that the feedback signal injected into the RL buffer is clean, objective, and mathematically actionable.
Quiz 5: Derive the mathematical balance condition for worker allocation in an asynchronous RL framework like
Let be the number of generation nodes, be the number of training nodes, be the rollout batch size per generation node, be the training batch size, be the time per generation step, and be the time per training step. If the trajectory admission rate (fraction of trajectories that pass validation) is , where , the admitted generation throughput is trajectories per second. The training throughput is trajectories per second. To prevent training buffer starvation or continuous overflow, we must balance these rates: . Rearranging for the optimal worker ratio yields: . This equation dictates how engineers dynamically scale rollout nodes relative to training nodes as admission filters get stricter (smaller ).slime to prevent training starvation, assuming Trajectory Admission Control.
References
- Zeng, A., et al. (2026). GLM-5: from Vibe Coding to Agentic Engineering. arXiv:2602.15763.
- THUDM. (2025). slime: An LLM post-training framework for RL scaling. GitHub.
- DataComp-LM (DCLM) authors. (2024). DataComp for Language Models. arXiv:2406.11794.