12.2 PagedAttention (vLLM)
As established in the previous section, the KV cache is the primary bottleneck in autoregressive LLM serving. While architectural innovations like Multi-Head Latent Attention (MLA) and quantization reduce the absolute size of the cache, they do not solve the fundamental systems-engineering problem: how that memory is allocated and managed.
Prior to 2023, standard inference backends (such as HuggingFace Transformers) allocated KV cache memory contiguously. Because the final length of a user’s generated response is unknown at the start of a request, systems were forced to over-allocate memory based on the model’s maximum context window. This naive approach resulted in a catastrophic waste of High Bandwidth Memory (HBM), severely limiting the number of concurrent requests a GPU could handle.
The solution to this bottleneck did not come from a new neural network architecture, but from a classic Operating Systems concept from the 1960s: Virtual Memory. The resulting algorithm, PagedAttention, forms the core of the vLLM engine and fundamentally redefined the economics of LLM serving.
1. The Fragmentation Crisis
To understand why PagedAttention was revolutionary, we must examine the memory profile of a naive LLM serving system. When contiguous memory allocation is used for dynamic sequence generation, two types of fragmentation occur:
- Internal Fragmentation: A system receives a prompt and must allocate a contiguous chunk of memory for the KV cache. Because it doesn’t know if the model will generate 10 tokens or 1,000 tokens, it allocates memory for the maximum possible sequence length (e.g., 2,048 tokens). If the model only generates 20 tokens and stops, the remaining 2,028 tokens’ worth of memory is reserved but entirely unused.
- External Fragmentation: As requests of varying lengths finish at different times, contiguous chunks of memory are freed, leaving small “holes” in the GPU VRAM. These holes might collectively sum to a large amount of memory, but because they are not contiguous, they cannot be used to allocate a new, large request.
Studies by the vLLM team revealed that in standard serving systems, 60% to 80% of KV cache memory was wasted due to fragmentation and over-reservation. Only 20% to 40% was actually storing useful tensor data.
2. The OS Inspiration: Paging and Block Tables
In modern Operating Systems, physical RAM is not allocated to applications in large, contiguous chunks. Instead, memory is divided into fixed-size “pages.” The application sees a contiguous logical memory space, but the OS maps this to non-contiguous physical pages using a Page Table.
PagedAttention applies this exact paradigm to the KV cache:
- Logical Blocks: The sequence of tokens in a user’s request is divided into logical blocks (e.g., 16 tokens per block).
- Physical Blocks: The GPU VRAM is pre-divided into a massive pool of fixed-size physical blocks.
- Block Table: A mapping table tracks which physical block corresponds to which logical block for a given request.
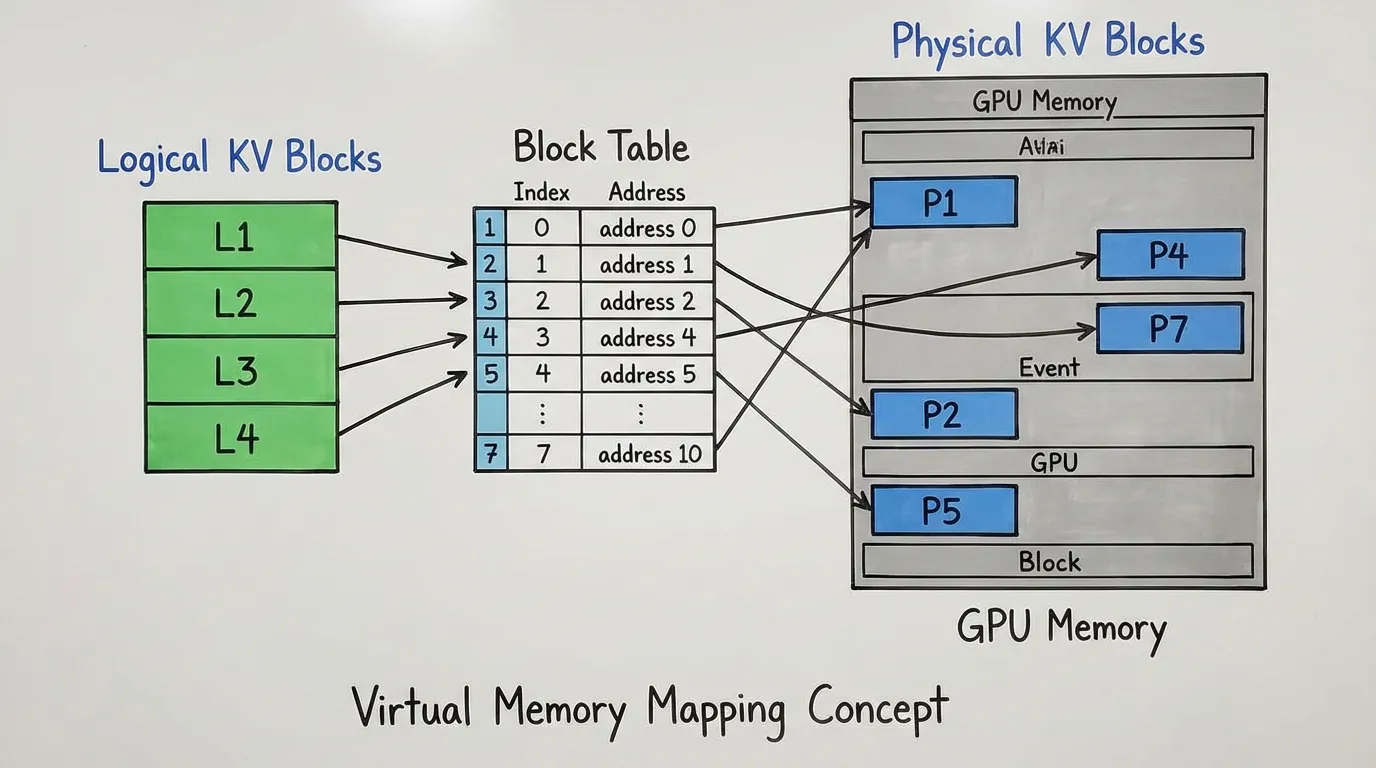
When a request begins, the engine only allocates enough physical blocks to hold the initial prompt. As the model generates new tokens autoregressively, the system allocates new physical blocks on demand.
Because blocks are fixed in size and non-contiguous, external fragmentation is completely eliminated. Internal fragmentation is reduced to only the unused slots in the final block of a sequence (typically less than 4% waste).
Interactive PagedAttention Simulation
The following interactive component demonstrates how logical blocks are mapped to physical blocks dynamically. Notice how generating tokens only consumes memory when a block boundary is crossed, and how freeing a request leaves non-contiguous gaps that are perfectly usable by new requests.
PagedAttention Memory Allocator
Logical View (Requests)
Physical VRAM (Blocks)
3. Engineering PagedAttention (PyTorch Simulation)
In a production environment, PagedAttention is implemented as a highly optimized, fused custom CUDA kernel. The kernel reads the Block Table directly and fetches the non-contiguous Key and Value tensors on the fly during the matrix multiplication.
However, to deeply understand the mechanics, we can construct a functional PyTorch simulation. The following code demonstrates how a central memory pool is managed and how attention is computed over non-contiguous physical blocks.
import torch
import torch.nn.functional as F
class KVCacheMemoryPool:
def __init__(self, num_blocks, block_size, num_heads, head_dim, dtype=torch.float16):
self.num_blocks = num_blocks
self.block_size = block_size
# Physical VRAM Pool: [num_blocks, 2 (K&V), num_heads, block_size, head_dim]
self.physical_memory = torch.zeros(
(num_blocks, 2, num_heads, block_size, head_dim),
dtype=dtype,
device='cuda'
)
self.free_blocks = list(range(num_blocks)[::-1]) # Stack of free block indices
def allocate_block(self):
if not self.free_blocks:
raise RuntimeError("Out of Memory: No free KV blocks available.")
return self.free_blocks.pop()
def free_block(self, block_idx):
self.free_blocks.append(block_idx)
def paged_attention_simulated(query, physical_pool, block_table, context_len):
"""
Simulates the PagedAttention kernel logic in pure PyTorch.
query: [1, num_heads, 1, head_dim] (The current token's query)
physical_pool: The KVCacheMemoryPool object
block_table: List of physical block indices for this specific sequence
context_len: Total number of valid tokens in the sequence
"""
num_heads = query.size(1)
head_dim = query.size(3)
block_size = physical_pool.block_size
# 1. Reconstruct the contiguous K and V tensors from the non-contiguous physical blocks
# Note: In the actual CUDA kernel, this explicit reconstruction is bypassed,
# and the dot product is computed directly block-by-block to save memory bandwidth.
keys = []
values = []
for block_idx in block_table:
# Fetch physical block: [num_heads, block_size, head_dim]
k_block = physical_pool.physical_memory[block_idx, 0]
v_block = physical_pool.physical_memory[block_idx, 1]
keys.append(k_block)
values.append(v_block)
# Concatenate blocks along the sequence dimension
# Shape: [num_heads, total_allocated_len, head_dim]
contiguous_k = torch.cat(keys, dim=1)
contiguous_v = torch.cat(values, dim=1)
# 2. Truncate the padded tokens in the final block using context_len
contiguous_k = contiguous_k[:, :context_len, :]
contiguous_v = contiguous_v[:, :context_len, :]
# 3. Add batch dimension for PyTorch compatibility
contiguous_k = contiguous_k.unsqueeze(0)
contiguous_v = contiguous_v.unsqueeze(0)
# 4. Compute standard scaled dot-product attention
# FlashAttention can be applied here in a real scenario
attn_output = F.scaled_dot_product_attention(query, contiguous_k, contiguous_v)
return attn_outputNote: The actual vLLM CUDA kernel does not concatenate the blocks into a contiguous tensor as shown in step 1 above. Instead, it iterates through the block_table, computes the partial attention scores block-by-block, and accumulates the results using the same mathematical identity found in FlashAttention. This ensures the peak memory footprint remains negligible.
4. Advanced Memory Management: Copy-on-Write (CoW)
By decoupling logical blocks from physical memory, PagedAttention unlocks advanced memory-sharing capabilities that were previously impossible or highly inefficient.
Consider Parallel Sampling or Beam Search, where a single prompt is passed to the model, and the model generates multiple different candidate responses simultaneously. In traditional systems, the KV cache for the shared prompt had to be duplicated in memory for every candidate sequence, wasting massive amounts of VRAM.
With PagedAttention, vLLM implements Copy-on-Write (CoW):
- All candidate sequences share the exact same logical-to-physical block mapping for the prompt. The physical blocks simply maintain a reference count.
- As the sequences begin generating new tokens, they share the physical blocks until a sequence diverges.
- When a sequence needs to write a new token to a shared block, the system detects the reference count is , allocates a new physical block, copies the shared data, and updates that specific sequence’s Block Table.
This CoW mechanism reduces memory usage by up to 55% in complex sampling scenarios, allowing for significantly larger batch sizes during Beam Search.
5. Case Study: The LMSYS Chatbot Arena
The real-world impact of PagedAttention is best illustrated by its origins. vLLM was developed by researchers at UC Berkeley and was the driving force behind the massive success of the LMSYS Chatbot Arena and the Vicuna model releases in early 2023 [1].
LMSYS, operating as a small academic research team, had limited access to university-sponsored GPUs. When Vicuna launched, the traffic spikes were immense. Using the standard HuggingFace Transformers backend, their servers constantly crashed with Out-Of-Memory (OOM) errors, severely limiting the number of users they could serve.
By switching the backend engine to vLLM, LMSYS achieved a 24x higher throughput than HuggingFace Transformers, and a 3.5x higher throughput than HuggingFace’s optimized Text Generation Inference (TGI).
The near-zero memory waste allowed vLLM to pack significantly more requests into a single batch. This massive increase in batch size drastically improved the system’s overall throughput (tokens per second across all users) without noticeably degrading the latency (time to first token) of individual requests. Ultimately, PagedAttention allowed LMSYS to handle 5x more traffic and cut their GPU operational costs by 50%, sustaining millions of users on limited hardware.
6. Summary and Open Questions
PagedAttention transformed LLM inference from a pure machine learning problem into a systems engineering discipline. By applying OS-level virtual memory concepts to GPU VRAM, it eliminated KV cache fragmentation and enabled efficient memory sharing via Copy-on-Write. Today, virtually all modern inference engines (including TensorRT-LLM and SGLang) utilize some form of block-based memory management inspired by vLLM.
However, as we efficiently pack more requests into a batch, we encounter a new problem: Scheduling. If Request A generates 10 tokens and Request B generates 1,000 tokens, how do we efficiently swap requests in and out of the GPU without stalling the entire batch? This leads us directly to the concept of Continuous Batching, which we will explore in the next section.
Quizzes
Quiz 1: How does PagedAttention specifically resolve the issue of External Fragmentation in the KV Cache?
External fragmentation occurs when free memory is split into small, non-contiguous chunks that cannot accommodate a large contiguous allocation. Because PagedAttention allocates memory in fixed-size, non-contiguous physical blocks and maps them logically via a Block Table, any free physical block can be utilized by any request, regardless of where it resides in VRAM. This completely eliminates external fragmentation.
Quiz 2: In the context of PagedAttention, what is the only scenario where Internal Fragmentation still occurs?
Internal fragmentation only occurs in the very last physical block of a sequence. If a logical block is defined as 16 tokens, and a sequence ends having used only 3 tokens of its final block, the remaining 13 token slots in that physical block are wasted. However, this waste is strictly bounded and negligible compared to allocating for the maximum context length.
Quiz 3: Why is the Copy-on-Write (CoW) mechanism particularly advantageous for Beam Search decoding?
In Beam Search, multiple candidate sequences share the exact same initial prompt and often share early generated tokens before diverging. CoW allows all these sequences to map to the same physical memory blocks for the shared context. Memory is only allocated when a specific sequence generates a unique token that diverges from the others, drastically reducing the memory footprint compared to duplicating the entire sequence history.
Quiz 4: Does using PagedAttention change the mathematical output or accuracy of the LLM compared to contiguous KV caching?
No. PagedAttention is an exact algorithmic optimization. It changes how the memory is stored and fetched, but the actual self-attention calculation (the dot products and softmax) remains mathematically identical to standard contiguous attention. It yields the exact same output logits.
Quiz 5: Formulate the mathematical internal fragmentation overhead of PagedAttention. Let the block size be tokens, sequence length of request be , and the memory footprint per token be bytes. Derive the exact fragmented memory formula for a batch of requests.
In PagedAttention, memory is allocated in fixed-size blocks of tokens. Internal fragmentation occurs only in the last allocated block of a sequence if it is not completely filled. The number of wasted token slots for request is . Therefore, the exact fragmented memory footprint in bytes for request is: . For a batch of requests, the total internal fragmentation overhead is . Assuming is uniformly distributed, the average wasted tokens per request approaches . Thus, the average total overhead for requests is approximately bytes.
References
- Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., … & Stoica, I. (2023). “Efficient Memory Management for Large Language Model Serving with PagedAttention”. Proceedings of the 29th Symposium on Operating Systems Principles (SOSP). arXiv:2309.06180