6.1 Data Engineering at Scale
In the previous chapter, we dissected the routing mechanisms of trillion-parameter Mixture of Experts (MoE) architectures. We saw how models like DeepSeek-V3 and Grok-1 decouple computational cost from parameter count, allowing them to absorb staggering amounts of world knowledge. But an architecture with infinite capacity is useless without the data to fill it.
To train a state-of-the-art foundation model in 2026, you do not just need a large dataset; you need an industrial-grade data supply chain capable of streaming tens of trillions of tokens into thousands of GPUs simultaneously, without a single bottleneck.
Historically, data engineering was about writing manual Extract, Transform, Load (ETL) pipelines to move static records into data warehouses. In the era of foundation models, this paradigm has collapsed. The sheer volume (petabytes of text, images, and audio) and the complexity of the data have forced a fundamental shift. Today, data engineering is the art of building autonomous, self-adapting systems. As AI models converge in their architectural capabilities, the primary differentiator—the true “moat” for any AI enterprise—is the proprietary data pipeline.
1. The Three-Tiered Evolution of Data Pipelines
The transition from traditional ETL to AI-native data orchestration can be categorized into a three-tiered evolutionary model. Understanding this progression is crucial for engineering systems that scale to foundation model requirements.
Level 1: Optimized Pipelines
This is the traditional big data era (e.g., Apache Spark, Hadoop). Engineers focus on the manual composition and parameterization of operators to maximize throughput. If a schema changes upstream or a data distribution shifts (e.g., a massive influx of a new language in a web crawl), the pipeline breaks. Human intervention is required to rewrite the transformation logic.
Level 2: Self-Aware Pipelines
As data volume outpaced human capacity to monitor it, pipelines became “self-aware.” These systems continuously monitor their internal states and data distributions. Using statistical profiling, they detect “context rot” or schema drift before downstream failures occur. They do not fix the problem, but they generate high-signal alerts, preventing poisoned data from ruining a multi-million-dollar pre-training run.
Level 3: Self-Adapting Pipelines (SOTA 2026)
The current state-of-the-art. In a Level 3 system, data pipelines automatically react to changes in incoming data without human intervention. If an upstream source changes its schema, an AI agent intercepts the anomaly, generates the required SQL or Python transformation code, tests it in a sandbox, and deploys the fix dynamically. Data engineers have transitioned from writing pipeline code to supervising agentic orchestrators.
Data Pipeline Evolution
Evolution of data infrastructure for foundation model training.
Level 1: Optimized Pipelines
Manual ETL and batch processing. The pipeline breaks on schema changes, requiring human intervention.
- Manual ETL
- Static Schema
- High Human Dependency
Level 2: Self-Aware Pipelines
Continuously monitors data distribution and state. Detects anomalies and generates alerts, but cannot self-heal.
- Data Profiling
- Anomaly Detection
- Automated Alerts
Level 3: Self-Adapting Pipelines
AI agents detect data changes, dynamically generate and test transformation code, and self-heal the pipeline.
- Agent Orchestration
- Auto-remediation
- Dynamic Code Generation
2. Architectural Shifts for AI Workloads
To support Level 3 autonomy and the massive throughput required by GPU clusters, the underlying infrastructure of data engineering has been radically re-architected.
Metadata as the Control Plane
In legacy systems, metadata was used passively for data discovery (e.g., data catalogs). Today, metadata is the active control plane. By abstracting metadata from storage and compute, systems can achieve unified access across heavily fragmented environments. The orchestrator queries the metadata layer to determine exactly which data shards a specific GPU node should process, enabling deterministic, reproducible training runs even across distributed clusters.
Open Table Formats (OTFs)
Formats like Apache Iceberg [1], Delta Lake [2], and Apache Hudi have become the default foundation for AI data lakes. They provide ACID (Atomicity, Consistency, Isolation, Durability) transactions directly on top of raw object storage.
For foundation model training, OTFs are critical because they eliminate the need for a centralized database engine. A cluster of 10,000 GPUs can concurrently read the exact same snapshot of a petabyte-scale dataset directly from storage using the metadata manifest, completely bypassing traditional database bottlenecks.
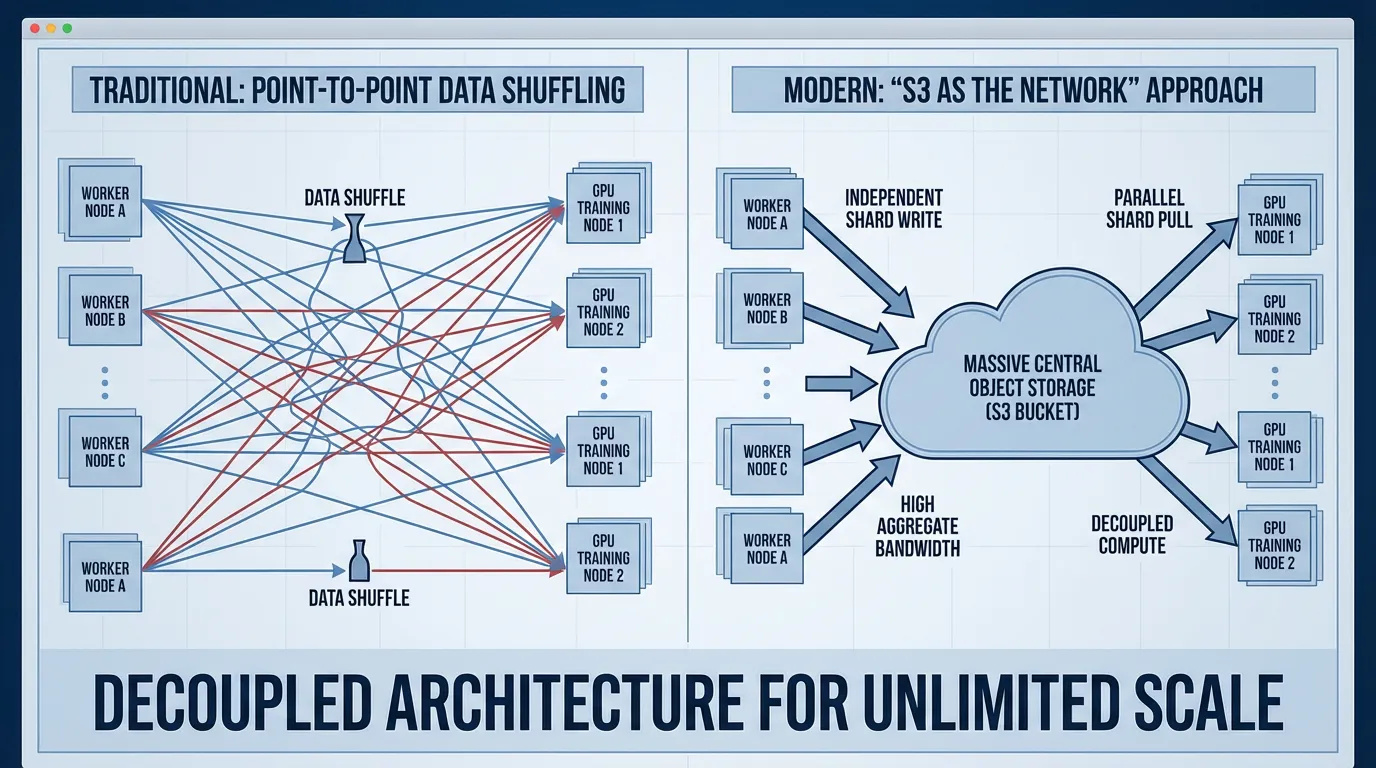
S3 as the Network
A counter-intuitive shift in large-scale AI engineering is treating cloud object storage (like Amazon S3 or Google Cloud Storage) as the primary network exchange medium. Traditional distributed systems rely heavily on direct network protocols (TCP/RPC) to shuffle data. However, at the scale of foundation models, point-to-point networking becomes a fragile bottleneck.
Instead, upstream processing nodes write heavily compressed, serialized tensor shards directly to object storage. Downstream training nodes pull these shards asynchronously. Object storage offers virtually infinite aggregate read bandwidth, effectively replacing complex network topologies with highly durable, parallelized HTTP GET requests.
3. Tensors and Vectors as First-Class Citizens
Traditional data pipelines were built for strings, integers, and timestamps. Pre-training a multimodal foundation model requires handling multi-dimensional arrays (tensors) and high-dimensional embeddings natively.
If you store images or audio as raw BLOBs and decode them on the GPU during training, you will instantly bottleneck your compute. The GPUs will idle while the CPUs struggle to decode JPEGs or MP3s.
Modern data engineering pushes this compute upstream. The data pipeline pre-processes, tokenizes, and serializes the data into raw tensor formats (e.g., .safetensors or optimized Parquet with tensor extensions) long before it reaches the training cluster.
Engineering Durable Execution for Tensor Streams
When streaming terabytes of tensors to GPUs, network interruptions or node failures are inevitable. We must implement durable execution—the ability for a data loader to checkpoint its exact state and resume seamlessly without feeding duplicate data to the model (which would cause loss spikes).
Below is a PyTorch implementation of a simplified, durable IterableDataset designed to read tensor shards from object storage. It tracks its internal state so that if the training job crashes, it can resume exactly where it left off.
import torch
import os
import json
from torch.utils.data import IterableDataset, DataLoader
from typing import Iterator, List, Dict
class DurableTensorStreamer(IterableDataset):
"""
A durable, stateful dataset designed for large-scale pre-training.
Streams pre-tokenized tensor shards and maintains a precise checkpoint of its state.
"""
def __init__(self, shard_uris: List[str], checkpoint_path: str, batch_size: int):
super().__init__()
self.shard_uris = shard_uris
self.checkpoint_path = checkpoint_path
self.batch_size = batch_size
# State tracking for durable execution
self.current_shard_idx = 0
self.current_sample_idx = 0
self._load_checkpoint()
def _load_checkpoint(self):
"""Loads the dataset state if a previous training run crashed."""
if os.path.exists(self.checkpoint_path):
with open(self.checkpoint_path, 'r') as f:
state = json.load(f)
self.current_shard_idx = state.get('shard_idx', 0)
self.current_sample_idx = state.get('sample_idx', 0)
print(f"Resuming data stream from Shard {self.current_shard_idx}, Sample {self.current_sample_idx}")
def save_checkpoint(self):
"""Called by the training loop after a successful model checkpoint."""
state = {
'shard_idx': self.current_shard_idx,
'sample_idx': self.current_sample_idx
}
# In production, this would write atomically to object storage
with open(self.checkpoint_path, 'w') as f:
json.dump(state, f)
def _download_and_load_shard(self, uri: str) -> torch.Tensor:
"""Simulates downloading a chunk of pre-tokenized data from S3."""
# In reality, use boto3 or cloud storage SDKs to pull .safetensors or .pt files
# Here, we simulate a shard of 10,000 sequences of length 4096
return torch.randint(0, 50257, (10000, 4096), dtype=torch.long)
def __iter__(self) -> Iterator[torch.Tensor]:
worker_info = torch.utils.data.get_worker_info()
# Handle multi-processing data loading by sharding the shards
if worker_info is not None:
per_worker = len(self.shard_uris) // worker_info.num_workers
worker_id = worker_info.id
start_idx = worker_id * per_worker
end_idx = start_idx + per_worker
worker_shards = self.shard_uris[start_idx:end_idx]
else:
worker_shards = self.shard_uris[self.current_shard_idx:]
for shard_idx, uri in enumerate(worker_shards):
# Absolute index for checkpointing
actual_shard_idx = self.current_shard_idx + shard_idx
# Load the tensor block into memory
tensor_block = self._download_and_load_shard(uri)
# Fast-forward if resuming from a crash mid-shard
start_sample = self.current_sample_idx if actual_shard_idx == self.current_shard_idx else 0
for i in range(start_sample, len(tensor_block), self.batch_size):
batch = tensor_block[i : i + self.batch_size]
# Yield the batch. The training loop must call save_checkpoint() periodically.
yield batch
# Update state
self.current_sample_idx = i + self.batch_size
# Reset sample index for the next shard
self.current_sample_idx = 0
self.current_shard_idx = actual_shard_idx + 1
# Example Usage:
# shards = [f"s3://bucket/dataset/shard_{i}.pt" for i in range(1000)]
# dataset = DurableTensorStreamer(shards, "./data_checkpoint.json", batch_size=32)
# dataloader = DataLoader(dataset, batch_size=None, num_workers=4) # batch_size=None because dataset yields batches4. Agentic Orchestration: The 630-Line Paradigm
As data engineering scales, human intervention becomes the primary bottleneck. At KubeCon 2026, Kelsey Hightower famously remarked, “Everyone is a junior engineer when it comes to AI.” This highlighted the steep learning curve as infrastructure shifted from declarative configurations to agentic workflows.
Consider an anecdote shared by Andrej Karpathy regarding modern AI engineering: A single 630-line Python script, utilizing an LLM agent, was able to spin up infrastructure, run 50 distinct data processing experiments overnight, analyze the failure logs, rewrite its own data transformation SQL, and push the cleaned data to the training cluster—all without human input.
This is the power of a “closed-loop” autonomous system. Data engineers are no longer writing the SQL joins to clean the Common Crawl dataset. Instead, they are defining the strict validation parameters and reward functions for the AI agents that write, test, and execute the SQL. The engineer’s role has elevated from builder to supervisor, focusing on the architectural integrity and security of the pipeline rather than the syntax of the transformations.
5. Summary & Next Steps
Data engineering at the scale of foundation models is a masterclass in distributed systems design. We have moved from manual ETL scripts to self-adapting, agent-orchestrated pipelines. We have decoupled storage from compute using Open Table Formats, elevated metadata to the control plane, and re-architected our datasets to treat tensors as first-class citizens.
However, before we can stream these tensors into the GPUs, we must confront a fundamental question: How do we convert human language, code, and raw bytes into the dense integer sequences that a neural network can actually process?
In the next section, 6.2 Tokenization Science, we will dive into the mathematics and engineering of token compression. We will explore why Byte-level BPE won the tokenization war, how vocabulary size impacts model efficiency, and why a poorly optimized tokenizer can artificially cripple a model’s reasoning capabilities.
Quizzes
Quiz 1: A distributed training cluster of GPUs processes a micro-batch of sequences of length for multimodal pre-training. Each sequence includes text tokens (4 bytes/token) and pre-processed vision embeddings of dimension with vision tokens (float16, 2 bytes). Calculate the minimum aggregate network bandwidth (in Gbps) required from the data lake to sustain a step time of without GPU starvation.
First, calculate the data size per sequence: Text bytes = . Vision bytes = . Total per sequence = . Total global batch size in bytes = . Required aggregate bandwidth = . In Gbps (Gigabits per second) = .
Quiz 2: In a Level 3 “Self-Adapting” pipeline, what is the primary role of the human data engineer?
In a Level 3 pipeline, the system automatically detects anomalies (like schema drift) and uses AI agents to generate and deploy code fixes. The human data engineer transitions from manually writing ETL code to acting as a supervisor. They focus on defining validation parameters, setting up the guardrails/reward functions for the AI agents, and ensuring the overall architectural integrity and security of the system.
Quiz 3: Why is it a critical anti-pattern to store raw multimodal data (like JPEGs or MP3s) in the data lake and decode them directly on the GPU nodes during foundation model pre-training?
GPUs are optimized for massive parallel matrix multiplications, not sequential file decoding. If raw files are sent to the training cluster, the CPUs on the training nodes will become a severe bottleneck trying to decode the media, causing the highly expensive GPUs to idle (starvation). Modern pipelines push this compute upstream, decoding and serializing the data into raw multi-dimensional tensors (e.g., .safetensors) before it ever reaches the training cluster.
Quiz 4: How do Open Table Formats (OTFs) like Apache Iceberg solve the centralized database bottleneck for distributed GPU training?
OTFs abstract the metadata from the storage and compute layers, allowing ACID transactions directly on raw object storage. Because the metadata manifest explicitly maps out exactly where all data shards live, a distributed cluster of 10,000 GPUs can concurrently read the exact same snapshot of a dataset directly from storage. This entirely bypasses the need for a centralized database engine, which would crash under the concurrent connection load.
References
- Apache Software Foundation. (2024). Apache Iceberg: A Table Format for Huge Analytic Datasets. Link.
- Armbrust, M., et al. (2020). Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proceedings of the VLDB Endowment. arXiv:2008.06750.