17.4 Contamination Issues
In forensic fire investigation, determining whether a fire was an accident or arson relies on detecting Ignitable Liquid Residues (ILRs) like gasoline. However, modern household materials—carpets, adhesives, and plastics—are petroleum-based. When they burn, they undergo pyrolysis, releasing compounds that perfectly mimic ILRs. If an investigator fails to establish a clean baseline or reuses gloves across different scenes, they introduce trace contaminants. The result is a “false positive”: the chemical analysis screams arson, but no crime actually occurred.
In Foundation Model engineering, evaluating a Large Language Model (LLM) on a benchmark like MMLU or HumanEval is our attempt to detect the “spark” of genuine generalization. However, if the model’s training corpus inadvertently included the benchmark’s test set—through aggressive web scraping, synthetic data leakage, or improper deduplication—the resulting benchmark score is a false positive. The model has not learned to reason; it has simply memorized the crime scene.
This phenomenon, known as Data Contamination, is currently the most significant threat to the integrity of AI evaluation [1]. As pre-training corpora scale to tens of trillions of tokens, completely isolating evaluation data has transitioned from a trivial filtering task to a massive distributed systems challenge.
🧪 Case Study: The MMLU Contamination Controversy
MMLU (Massive Multitask Language Understanding) is the industry standard, but it has become a victim of its own success. As models are increasingly trained on massive web crawls, the benchmark itself has likely leaked into the training data.
Technical Deep Dive:
- The “Data Contamination Quiz”: Researchers found that many SOTA models could perfectly reconstruct MMLU questions when given a short prefix, indicating direct memorization rather than reasoning.
- Sensitivity to Shuffling: In a famous study, a model’s score dropped by over 15% simply by changing the multiple-choice labels (A, B, C, D) to numbers or reordering the choices. This suggests the model was relying on positional bias and memorized answer keys.
The Engineering Impact:
- Benchmarking Arms Race: This controversy has led to the development of “Contamination-Free” versions of benchmarks (e.g., MMLU-CF) and the use of n-gram overlap analysis to filter out test sets from training data.
- Model Evaluation: It highlights the need for canary tokens and private test sets to ensure true generalization.
Key Lesson: A high benchmark score is meaningless without a rigorous check for data leakage.
Reference: Golchin, S., & Surdeanu, M. (2023). “Is Your Model Bright or Just Memorizing?”
The Anatomy of Data Contamination
Contamination is not a binary state. It exists on a spectrum of severity and occurs at different phases of the model lifecycle.
Phase-Based Contamination
- Pre-training Leakage: The most common vector. Benchmarks like GSM8K or MMLU are widely discussed on GitHub, Reddit, and educational forums. When web crawlers (e.g., Common Crawl) scrape the internet, they ingest these discussions. Despite deduplication efforts, fragments of the test set inevitably slip into the pre-training corpus.
- Post-training (SFT/RLHF) Leakage: A more insidious vector. During Supervised Fine-Tuning (SFT), engineers often rely on synthetic data generated by stronger frontier models (like GPT-4). If the teacher model was contaminated, or if the synthetic generation prompt inadvertently requested tasks similar to the benchmark, the student model inherits this contamination semantically.
Type-Based Contamination
- Exact Match (Verbatim) Contamination: The training data contains the exact string of the evaluation prompt and its target answer.
- Input-Only Contamination: The model saw the benchmark question during training, but not the answer. While less severe than exact match, it still artificially inflates performance by familiarizing the model with the specific syntax and distribution of the test set.
- Semantic (Paraphrased) Contamination: The training data contains the logical equivalent of the benchmark question, but with swapped entities or rephrased text (e.g., changing “Alice has 3 apples” to “Bob holds 3 oranges”). This easily bypasses traditional string-matching filters [2].
Detection at Scale: The Math of Deduplication
Detecting exact match contamination requires comparing the evaluation benchmark against the entire pre-training corpus. The standard metric for measuring the overlap between two text documents is the Jaccard Similarity.
Given a document , we extract a set of contiguous -grams (typically ), denoted as . The Jaccard similarity between a training document and a benchmark document is:
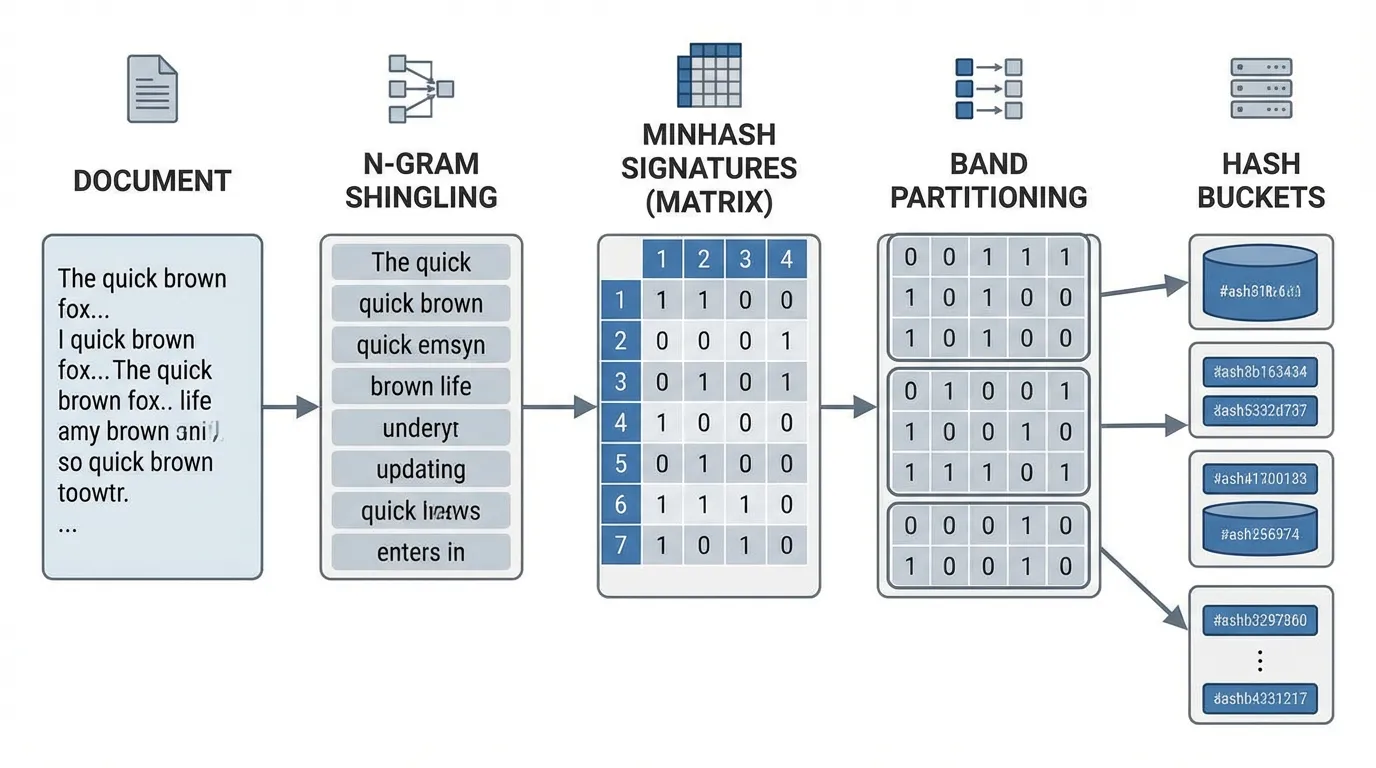
Computing this exactly for a trillion-token corpus (e.g., documents) against a benchmark suite requires comparisons, which is computationally infeasible. To solve this, engineers utilize MinHash combined with Locality-Sensitive Hashing (LSH) [4].
MinHash Signatures
MinHash is a probabilistic technique that approximates Jaccard similarity. A hash function maps the elements of the universal set of -grams to distinct integers. The MinHash of set is the minimum hash value:
The mathematical magic of MinHash is that the probability of the MinHash values of two sets colliding is exactly their Jaccard similarity:
By using independent hash functions, we create a compact “signature vector” for each document. The Jaccard similarity is estimated by counting the number of matching values in the two signatures.
Locality-Sensitive Hashing (LSH)
Even with compact signatures, an scan per benchmark question is too slow. LSH divides the -dimensional signature into bands of rows ().
Each band is hashed into a bucket. If two documents share identical values in any of the bands, they are flagged as a candidate pair for exact Jaccard calculation. The probability that two documents become a candidate pair is:
This creates a steep step function. By tuning and , engineers can strictly filter out dissimilar documents while guaranteeing near 100% recall for documents with a Jaccard similarity above a specific threshold (e.g., 0.8).
Engineering the Decontamination Pipeline
Implementing a robust decontamination pipeline requires vectorizing the MinHash generation to utilize GPU or distributed CPU clusters efficiently. Below is a foundational PyTorch implementation demonstrating how to generate signatures for a batch of documents and estimate contamination against a benchmark.
import torch
import hashlib
from typing import List, Set
def generate_ngrams(text: str, n: int = 13) -> Set[str]:
"""Generates word n-grams from a document to capture local syntactic structure."""
tokens = text.lower().split()
return set([" ".join(tokens[i:i+n]) for i in range(len(tokens) - n + 1)])
def compute_minhash_signatures(documents_ngrams: List[Set[str]], num_hashes: int = 128) -> torch.Tensor:
"""
Computes MinHash signatures for a batch of documents using vectorized operations.
Returns a tensor of shape (batch_size, num_hashes).
"""
batch_size = len(documents_ngrams)
signatures = torch.full((batch_size, num_hashes), float('inf'), dtype=torch.int64)
# Deterministic linear congruential generator (LCG) parameters
# h_i(x) = (a_i * x + b_i) % p
torch.manual_seed(42) # Fixed seed for reproducibility across pipeline runs
p = 2**31 - 1
a = torch.randint(1, p, (num_hashes,), dtype=torch.int64)
b = torch.randint(0, p, (num_hashes,), dtype=torch.int64)
for doc_idx, ngrams in enumerate(documents_ngrams):
for ngram in ngrams:
# Convert n-gram to a base 64-bit integer hash (using MD5 prefix for speed)
base_hash = int(hashlib.md5(ngram.encode('utf-8')).hexdigest()[:15], 16)
# Compute all K hash functions for this n-gram simultaneously
hash_vals = (a * base_hash + b) % p
# Update the minimum values for this document's signature
signatures[doc_idx] = torch.minimum(signatures[doc_idx], hash_vals)
return signatures
def check_contamination(doc_sigs: torch.Tensor, benchmark_sig: torch.Tensor, threshold: float = 0.8) -> torch.Tensor:
"""
Estimates Jaccard similarity across a batch and flags contamination.
Returns a boolean tensor of shape (batch_size,).
"""
# doc_sigs: (batch_size, num_hashes)
# benchmark_sig: (num_hashes,)
matches = (doc_sigs == benchmark_sig).float()
estimated_jaccard = matches.mean(dim=1) # Shape: (batch_size,)
return estimated_jaccard >= thresholdInteractive N-Gram Overlap Analysis
To intuitively understand how -gram size affects contamination detection, use the visualizer below. Notice how a small (e.g., ) results in high false positives due to common grammatical structures, while a high (e.g., ) might miss semantic paraphrasing.
Interactive N-Gram Overlap Analysis
Text A N-Grams
- "the quick brown"
- "quick brown fox"
- "brown fox jumps"
- "fox jumps over"
- "jumps over the"
- "over the lazy"
- "the lazy dog"
Text B N-Grams
- "a quick brown"
- "quick brown fox"
- "brown fox leaps"
- "fox leaps over"
- "leaps over a"
- "over a lazy"
- "a lazy dog"
Beyond Exact Match: Semantic and Dynamic Benchmarking
While MinHash LSH is the industry standard for catching verbatim leakage, it is fundamentally blind to semantic contamination. As LLMs become more capable, the evaluation paradigm is shifting to address these blind spots [2], [3].
1. Embedding-Based Detection
To catch paraphrased benchmarks, engineers employ dense retrieval models (e.g., E5, BGE). Both the benchmark questions and the training documents are projected into a latent vector space. If the cosine similarity between a training document and a test question exceeds a threshold, the document is flagged. Because running dense embeddings over trillions of tokens is cost-prohibitive, this is usually applied strictly to the high-quality SFT datasets rather than the raw pre-training web crawl.
2. Perturbation Testing
How do we prove a model’s high score is due to contamination rather than genuine intelligence? We perturb the benchmark. By programmatically swapping entities (e.g., changing names, numbers, or specific conditions) in the test set, we create a logically identical task with a different surface string. If a model achieves 90% on the standard MMLU but drops to 45% on the perturbed MMLU, it indicates catastrophic memorization. The model learned the specific token sequence of the benchmark, not the underlying reasoning required to solve it [3].
3. Canary Insertion
Taking inspiration from software security, researchers inject “canaries”—unique, randomly generated cryptographic strings (e.g., 2b3c4d5e-test-canary-ignore)—into benchmark datasets before they are published to the web. If a newly trained model is prompted to autocomplete the text surrounding the canary and successfully outputs the UUID, it definitively proves the model was exposed to that dataset during pre-training.
4. Dynamic Benchmarking
The ultimate defense against contamination is retiring static benchmarks entirely. Dynamic benchmarking involves continuously generating new test sets using programmatic rules or frontier models, ensuring the evaluation data has a timestamp strictly after the model’s training cutoff date. Platforms like LiveBench and Chatbot Arena operate on this principle, rendering historical pre-training leakage irrelevant.
Quizzes
Quiz 1: Why is exact n-gram matching insufficient for detecting contamination in modern Instruction Tuning (SFT) datasets?
SFT datasets are frequently generated synthetically using other advanced LLMs (like GPT-4). These teacher models tend to paraphrase, reformat, or alter the entities of the original benchmark questions. This semantic contamination evades exact string matching (n-grams), requiring embedding-based similarity or LLM-as-a-judge approaches to detect.
Quiz 2: In the context of MinHash LSH, what happens if we increase the number of rows per band while keeping the number of bands constant?
Increasing makes the condition for matching within a band stricter, as all hash values must match perfectly. This decreases the probability of false positives (unrelated documents hashing to the same bucket) but increases the risk of false negatives (missing near-duplicates). It effectively shifts the LSH probability step function to the right, requiring a higher Jaccard similarity for two documents to become candidates.
Quiz 3: Suppose a model achieves 85% on a coding benchmark, but when the variable names in the prompts are randomly altered, the accuracy drops to 30%. What does this indicate about the model’s learning process?
This massive performance drop strongly suggests data contamination and pure memorization. If the model had learned genuine logical reasoning or algorithmic generalization, it would be robust to superficial variable name swaps. The model merely memorized the specific token sequences of the benchmark’s GitHub repository rather than the underlying programming logic.
Quiz 4: Why is “Input-Only Contamination” (where the model sees the question but not the answer) still considered a severe risk to benchmark integrity?
Even without the answer, exposure to the input familiarizes the model with the specific syntax, vocabulary distribution, and formatting of the test set. During pre-training, this shifts the model’s internal representations closer to the benchmark’s manifold. At inference time, the model expends less capacity parsing the prompt and is statistically more likely to generate a coherent continuation, artificially inflating its score compared to truly unseen, out-of-distribution tasks.
Quiz 5: Formalize the sequence of logic used to derive an aggregated Contamination Score utilizing contiguous n-grams. Define the explicit mathematical boundaries for exact match vs semantic contamination.
The contamination score is formalized as the cardinality of the intersection of n-gram sets normalized by benchmark length: . Exact match contamination flags sequences where contiguous match thresholds sit at (with and ). Semantic contamination bypasses string limits and is measured via latent vector cosine distance: . If , the sequence is flagged regardless of contiguous n-gram misses.
References
- Balloccu, F., et al. (2024). A Survey on Data Contamination for Large Language Models. arXiv:2402.02823.
- Chen, S., Chen, Y., Li, Z., Jiang, Y., Wan, Z., He, Y., Ran, D., Gu, T., Li, H., Xie, T., & Ray, B. (2025). Benchmarking Large Language Models Under Data Contamination: A Survey from Static to Dynamic Evaluation. ACL Anthology.
- Ishikawa, Y. (2025). Data Contamination or Genuine Generalization? Disentangling LLM Performance on Benchmarks. Academic Journal of Natural Science.
- Milvus Documentation (2025). MINHASH_LSH: Large-Scale Deduplication and Similarity Search. Zilliz.