15.1 Chain of Thought Prompting
Large Language Models (LLMs) excel at many tasks, but they often struggle with complex reasoning, such as multi-step math problems or symbolic logic. Chain of Thought (CoT) Prompting, introduced by Wei et al. in 2022 [1], is a simple yet powerful technique that dramatically improves the reasoning capabilities of LLMs by encouraging them to generate a sequence of intermediate resolving steps.
The Core Concept: Thinking Step by Step
Standard prompting directly asks the model for an answer, which often leads to errors in complex tasks because the model tries to map the input directly to the output in a single pass. CoT prompting, on the other hand, provides the model with a few examples where the reasoning process is explicitly shown, or simply instructs the model to “think step by step.”
By generating intermediate steps, the model effectively breaks down a complex problem into smaller, manageable sub-problems. This allows the model to allocate more compute (in the form of generated tokens) to the reasoning process.
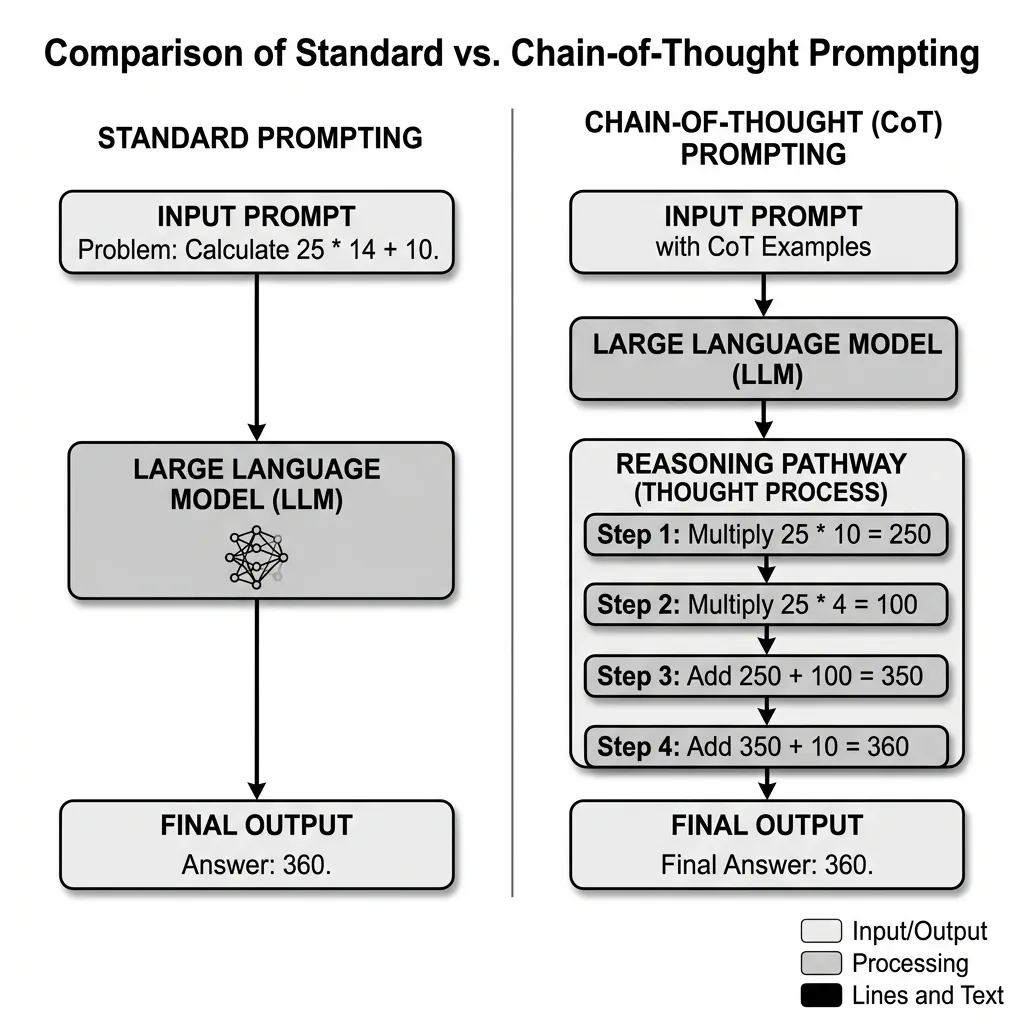 Source: Generated by Gemini
Source: Generated by Gemini
Zero-Shot CoT: The Magic Phrase
While few-shot CoT requires providing examples, Kojima et al. (2022) [2] discovered that simply adding the phrase “Let’s think step by step” to the prompt elicits similar reasoning behavior without any examples. This is known as Zero-Shot CoT.
This simple addition triggers the model to generate a reasoning pathway before arriving at the final answer, significantly improving accuracy on benchmarks like GSM8K (math word problems).
When CoT Helps and When It Hurts
CoT is most useful when the task really does benefit from decomposition: arithmetic word problems, symbolic manipulation, constrained planning, or cases where the model needs to keep track of intermediate variables.
It is much less useful when the task is primarily:
- factual lookup
- shallow classification
- retrieval with direct citation
- or any setting where verbose intermediate text mainly adds latency without improving correctness
There is also a failure mode that newcomers often miss: a longer reasoning trace can make an answer sound more convincing even when the logic is wrong. In other words, CoT improves many reasoning tasks, but it can also amplify overconfidence if the intermediate steps are not checked.
Visible Reasoning vs. Production Interfaces
In research papers, CoT is often displayed directly because the reasoning text is the object of study. In production, teams frequently separate the two concerns:
- use reasoning internally, but return only the answer and evidence
- force the final answer into a strict schema
- or run verification on the final result rather than trusting the prose of the reasoning trace
This is why CoT is best understood as extra test-time compute expressed in tokens, not as a guarantee that the explanation is faithful or sufficient by itself.
Implementing Chain of Thought in Production
For developers building applications with LLMs, CoT is a must-know technique. However, it introduces several challenges in production environments.
1. The Output Parsing Challenge
When a model generates a chain of thought, the final answer is buried within the text. Developers need a reliable way to extract it.
Strategy A: Prompting for a Specific Format Instruct the model to put the final answer in a specific XML tag or JSON field at the very end.
“At the end of your reasoning, provide the final answer in the format: <answer>FINAL_ANSWER_HERE</answer>.”
Strategy B: Post-Processing with Regular Expressions Use regex to find common patterns or the specified tags.
2. Self-Consistency: Improving Reliability
CoT reasoning can sometimes go off the rails. To improve reliability, Wang et al. (2022) [3] proposed Self-Consistency. Instead of generating a single chain of thought, the model generates multiple reasoning paths (e.g., 5 or 10) by setting a non-zero temperature. The system then aggregates the final answers (e.g., by majority vote) to find the most consistent answer. This significantly reduces random errors.
PyTorch Simulation of CoT Logic
While CoT is a prompting technique, we can simulate the “step-by-step” token generation and verification process to understand how compute scales with reasoning steps.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleReasoningModel(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=embed_dim, nhead=4),
num_layers=2
)
self.output_layer = nn.Linear(embed_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
x = self.transformer(x)
return self.output_layer(x)
def generate_with_cot(model, prompt_tokens, max_steps=5):
"""
Simulate generating a sequence with intermediate reasoning steps.
"""
current_tokens = prompt_tokens
print(f"Initial Prompt: {current_tokens.tolist()}")
for step in range(max_steps):
# Predict next token (simulating one step of reasoning)
logits = model(current_tokens)
next_token_logits = logits[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
# Append to sequence
current_tokens = torch.cat([current_tokens, next_token], dim=1)
print(f"Step {step + 1} Reasoning Token: {next_token.item()}")
return current_tokens
# Example Usage
vocab_size = 100
embed_dim = 64
model = SimpleReasoningModel(vocab_size, embed_dim)
# Simulate a prompt
prompt = torch.tensor([[1, 2, 3]]) # Tokenized prompt
final_sequence = generate_with_cot(model, prompt, max_steps=4)
print(f"Final Sequence with CoT: {final_sequence.tolist()}")Quizzes
Quiz 1: Why does Chain of Thought prompting improve performance on complex reasoning tasks compared to standard prompting?
Standard prompting forces the model to map the input directly to the output in a single pass, which is hard for complex problems. CoT allows the model to generate intermediate steps, breaking the problem down and allocating more compute (tokens) to the reasoning process, leading to better accuracy.
Quiz 2: What is the main trade-off of using Chain of Thought prompting in a production API environment?
The main trade-off is increased latency and cost. CoT requires the model to generate many intermediate tokens before reaching the answer. Since LLM pricing is usually per token and speed is limited by autoregressive generation, CoT makes requests slower and more expensive.
Quiz 3: How does the Self-Consistency method improve the reliability of CoT reasoning?
Self-Consistency generates multiple independent reasoning paths for the same prompt by using non-zero temperature sampling. It then takes a majority vote of the final answers. This reduces the risk of the model making a random error in a single reasoning chain, as incorrect paths are likely to yield different answers, while correct paths will converge.
Quiz 4: Calculate the KV cache memory footprint for a reasoning model during CoT generation. Suppose the sequence length expands to tokens, the hidden dimension is , the number of attention heads is , the number of key-value heads is (Grouped Query Attention), the number of layers is , and the precision is FP16. Provide the explicit formula and derive the capacity for , , , , .
The KV cache memory footprint is calculated as: , where is the dimension per head. Here, . Plugging in the values: . This explicit capacity derivation shows how CoT generation, which significantly expands sequence length , leads to linear growth in memory footprint, potentially causing OOM issues without effective memory management.
References
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903.
- Kojima, T., et al. (2022). Large Language Models are Zero-Shot Reasoners. arXiv:2205.11916.
- Wang, X., et al. (2022). Self-Consistency Elicits CoT Reasoning in LLMs. arXiv:2203.11171.