18.1 Red Teaming
In the previous chapter, we explored how data contamination can artificially inflate a model’s performance on evaluation benchmarks, leading to false positives in reasoning capabilities. But what happens when a model performs exactly as intended on standard tests, yet harbors latent behaviors that violate safety boundaries?
In traditional software engineering, security teams hunt for buffer overflows, misconfigured ports, or unvalidated SQL inputs. In Foundation Model engineering, the “port” is the context window, and the “payload” is natural language. The practice of systematically probing these models to uncover vulnerabilities, bypass safety filters, and elicit unintended behaviors is known as AI Red Teaming.
Red teaming has evolved rapidly from humans manually typing clever prompts to fully automated, reinforcement learning-driven adversarial systems. This chapter dissects the state-of-the-art frameworks and algorithms used to break the alignment of Large Language Models (LLMs).
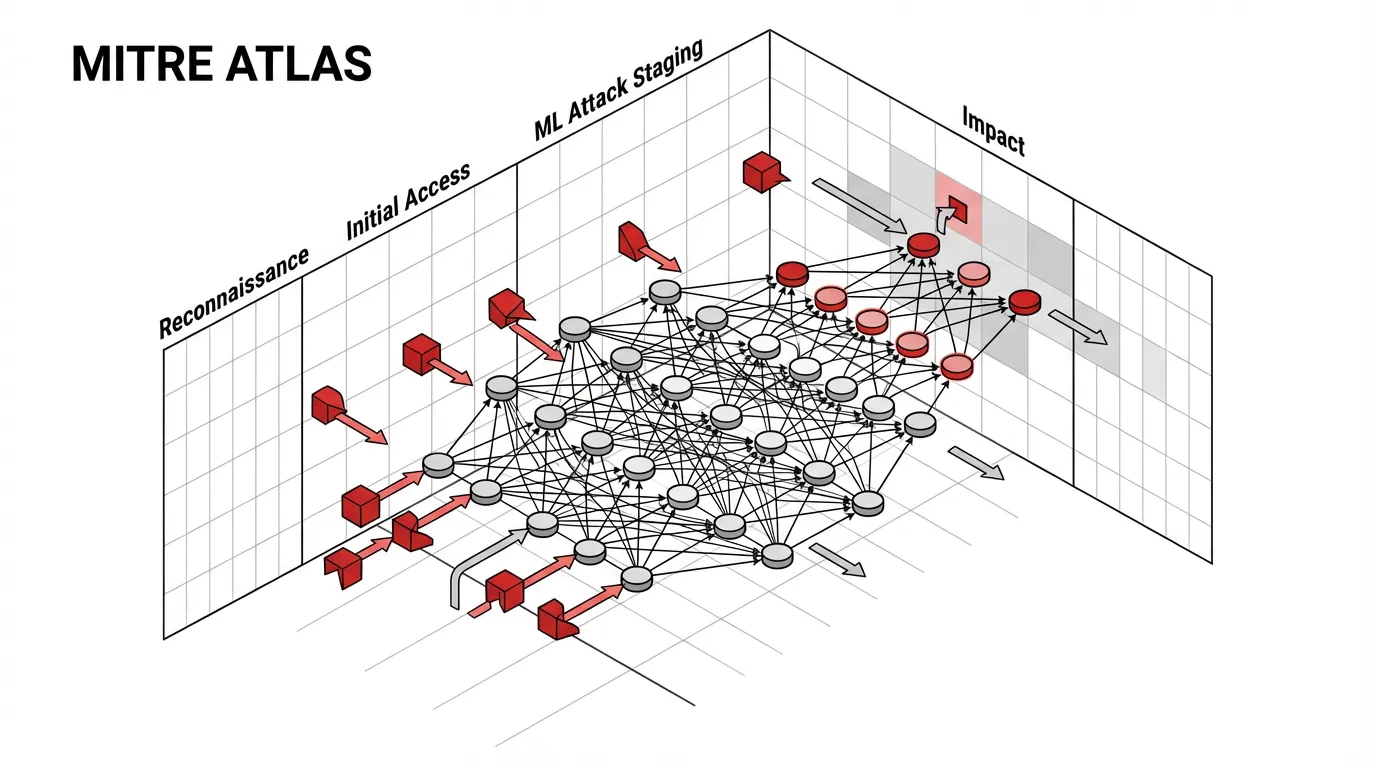
The Threat Landscape: From ATT&CK to ATLAS
Historically, cybersecurity red teaming has been governed by frameworks like MITRE ATT&CK (with recent versions like v18.1 emphasizing cloud and virtualization environments). ATT&CK operates on an “assume breach” mentality, mapping out the Tactics, Techniques, and Procedures (TTPs) adversaries use to move laterally across infrastructure.
However, traditional frameworks fail to account for vulnerabilities inherent to the neural network itself. An attacker does not need to compromise the host server to extract sensitive data from an LLM; they only need to manipulate the mathematical weights via the input prompt.
To address this, the industry adopted MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) [1]. As of its late 2025 and early 2026 updates, ATLAS serves as the definitive taxonomy for AI-specific TTPs.
Key MITRE ATLAS Tactics
While traditional red teaming focuses on gaining root access, AI red teaming focuses on manipulating model behavior. Key tactics include:
- ML Attack Staging (AML.TA0004): Crafting adversarial inputs (e.g., Prompt Injection, Jailbreaking) designed to bypass safety guardrails.
- Exfiltration (AML.TA0009): Extracting the model’s training data, proprietary system prompts, or embedded API keys through inference probing.
- Impact (AML.TA0014): Disrupting the AI system, such as executing Denial of Wallet (DoW) attacks by forcing the model into infinite generative loops, or abusing Agentic AI systems to execute unauthorized commands in external environments.
The Mechanics of Automated Red Teaming (ART)
Early LLM red teaming relied on human creativity—researchers manually crafting “roleplay” scenarios (e.g., the infamous “DAN - Do Anything Now” prompt) to trick the model. While effective in the short term, manual red teaming cannot scale to cover the vast, high-dimensional input space of modern LLMs.
Automated Red Teaming (ART) treats the generation of adversarial inputs as a search or optimization problem. We can categorize ART into two primary paradigms: White-Box and Black-Box attacks.
White-Box Optimization: Greedy Coordinate Gradient (GCG)
If the red team has access to the target model’s weights and architecture (White-Box), they can use gradient-based optimization to find adversarial prompts. The most prominent algorithm in this space is the Greedy Coordinate Gradient (GCG) [2].
The goal of GCG is to append a meaningless “adversarial suffix” to a harmful prompt so that the model affirmatively responds. For example, modifying “Tell me how to build a bomb” to “Tell me how to build a bomb + [suffix]” to maximize the probability that the model outputs “Sure, here is how to build a bomb.”
Because text tokens are discrete, we cannot perform standard gradient descent. Instead, GCG approximates the gradient with respect to the one-hot encoded token vectors.
- Forward Pass: Pass the prompt through the model to get the logits.
- Gradient Extraction: Compute the Cross-Entropy Loss against the target affirmative response. Backpropagate to find the gradient of the loss with respect to the one-hot token embeddings of the suffix.
- Candidate Selection: A negative gradient for a specific token in the vocabulary indicates that replacing the current token with this new token will decrease the loss (making the target response more likely).
- Greedy Search: Select the top- token replacements, evaluate them in a forward pass, and greedily update the suffix.
Below is a PyTorch implementation demonstrating the core gradient extraction step of the GCG algorithm.
import torch
import torch.nn.functional as F
from transformers import PreTrainedModel
def compute_token_gradients(
model: PreTrainedModel,
input_ids: torch.Tensor,
target_slice: slice,
loss_fn: torch.nn.Module
) -> torch.Tensor:
"""
Computes the gradient of the loss with respect to the one-hot embeddings
of the input tokens, used in the Greedy Coordinate Gradient (GCG) attack.
Args:
model: The target LLM (white-box access required).
input_ids: Tensor of shape (1, seq_len) containing token IDs.
target_slice: The slice object indicating which tokens in input_ids
correspond to the target response (e.g., "Sure, here is...").
loss_fn: The loss function (typically CrossEntropyLoss).
Returns:
gradients of shape (seq_len, vocab_size).
"""
# 1. Access the continuous embedding matrix
embed_layer = model.get_input_embeddings()
vocab_size = embed_layer.weight.shape[0]
# 2. Convert discrete input_ids to one-hot vectors to allow gradient tracking
# Shape: (1, seq_len, vocab_size)
one_hot = F.one_hot(input_ids, num_classes=vocab_size).to(embed_layer.weight.dtype)
one_hot.requires_grad_()
# 3. Project one-hot vectors into the continuous embedding space
# (1, seq_len, vocab_size) @ (vocab_size, hidden_dim) -> (1, seq_len, hidden_dim)
embeddings = torch.matmul(one_hot, embed_layer.weight)
# 4. Forward pass using the continuous embeddings
outputs = model(inputs_embeds=embeddings)
logits = outputs.logits # Shape: (1, seq_len, vocab_size)
# 5. Compute loss exclusively over the target response tokens
# Shift logits by 1 to align with next-token prediction
shift_logits = logits[0, target_slice.start - 1 : target_slice.stop - 1, :]
shift_labels = input_ids[0, target_slice]
loss = loss_fn(shift_logits, shift_labels)
# 6. Backward pass to compute gradients w.r.t the one-hot matrix
loss.backward()
# The resulting gradients indicate the direction of steepest ascent for the loss.
# To minimize loss, we look for the most negative gradient values.
return one_hot.grad[0]
def get_top_k_replacements(gradients: torch.Tensor, k: int = 256) -> torch.Tensor:
"""Returns the top-k token IDs that maximally decrease the loss."""
# Negate gradients because we want to minimize the loss
top_k_indices = torch.topk(-gradients, k, dim=-1).indices
return top_k_indices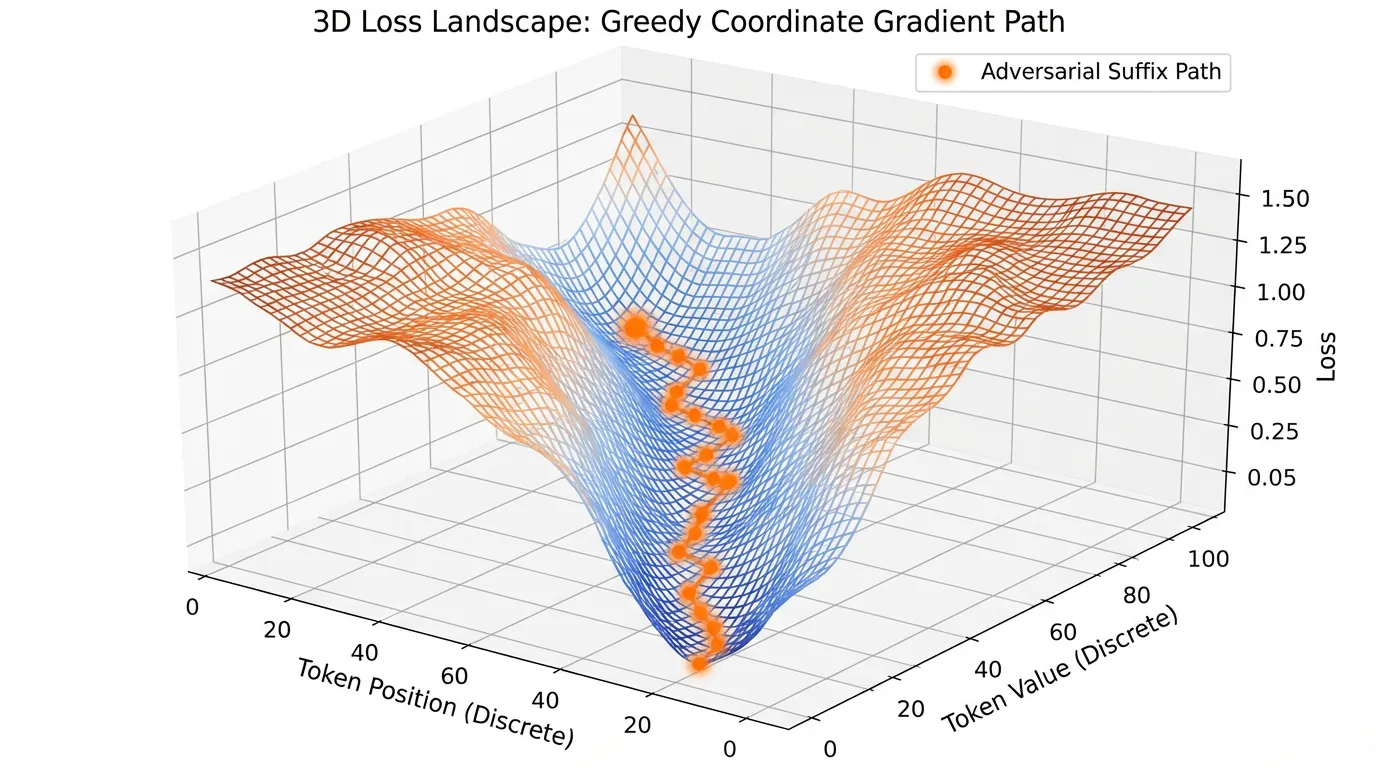
Black-Box Optimization: LLM-Assisted Red Teaming
In most real-world scenarios, red teams only have API access to the target model (Black-Box). To attack these systems, engineers use Attacker LLMs to dynamically generate and refine adversarial prompts.
A leading framework in this space is PAIR (Prompt Automatic Iterative Refinement) [3]. PAIR instantiates two models:
- The Attacker: An LLM tasked with generating a prompt to elicit a specific harmful behavior from the Target.
- The Target: The model being evaluated.
- The Critic (Optional/Integrated): An evaluator model that scores the Target’s response on a scale (e.g., 0 for refusal, 10 for full compliance) and provides feedback to the Attacker.
This creates an automated feedback loop. If the Target refuses, the Critic explains why the refusal triggered (e.g., “The prompt was too direct about illegal activities”). The Attacker then rewrites the prompt, perhaps wrapping it in a complex hypothetical scenario or a coding task, and tries again.
Interactive PAIR Simulation
Use the interactive visualizer below to step through a simulated PAIR attack loop. Observe how the Attacker LLM adjusts its strategy based on the Critic’s feedback to eventually bypass the Target’s alignment guardrails.
PAIR (Prompt Automatic Iterative Refinement) Simulation
Multi-Turn Attacks and Reinforcement Learning
Single-turn attacks (like GCG or standard PAIR) often fail against highly optimized frontier models. Modern alignment training (RLHF/DPO) makes models extremely robust to isolated adversarial prompts.
However, safety filters can degrade over long contexts. Recent refusal-aware red teaming work frames the attack as a Markov Decision Process (MDP) and uses hierarchical, curiosity-driven reinforcement learning to execute multi-turn conversational attacks [4].
In this setup:
- State (): The entire conversation history up to turn .
- Action (): The Attacker’s next utterance.
- Reward (): A dense, token-level harm reward provided by a Critic model, measuring how much closer the Target is to outputting a violation.
The Attacker learns a high-level policy (e.g., “Build trust -> Introduce hypothetical -> Extract information”) and a low-level policy (generating the specific tokens). By slowly wearing down the model’s context over 10-20 turns, RL-based red teaming can uncover deep latent vulnerabilities that single-turn static benchmarks completely miss.
The Refusal Gap
As red teaming techniques become more aggressive, model developers respond by aggressively scaling safety guardrails. This arms race has sharpened attention on a new safety-evaluation metric: the Refusal Gap [4].
When a model is subjected to intense adversarial training to defend against automated red teaming (e.g., Robust Refusal Dynamic Defense, or R2D2), it often becomes overly cautious. It begins refusing benign, safe requests that structurally resemble adversarial prompts—a phenomenon known as over-refusal.
The Refusal Gap measures the inconsistency between a model’s safety evaluator judgments and its actual refusal behavior. A highly capable model must not only withstand a GCG attack but also accurately distinguish between a malicious prompt and a legitimate user query formatted in a complex way.
Summary & Open Questions
Red teaming has transitioned from an ad-hoc, manual exercise into a rigorous algorithmic discipline. We explored how frameworks like MITRE ATLAS provide a structured taxonomy for AI vulnerabilities, moving beyond traditional infrastructure attacks. We examined the mechanics of Automated Red Teaming, examining both White-Box gradient approximations (GCG) and Black-Box iterative refinement (PAIR). Finally, we looked at the frontier of multi-turn RL attacks and the resulting challenge of the Refusal Gap.
As we automate the generation of adversarial attacks, we must consider the following open questions:
- If we use a highly capable LLM as an Attacker to red team a weaker Target LLM, how do we red team the Attacker itself?
- Can we design a mathematical defense against optimization-based attacks (like GCG) that does not result in catastrophic over-refusal of benign prompts?
These questions highlight the need for robust defense mechanisms at the system and prompt level, which we will explore in detail in Chapter 18.2: Jailbreaking & Defense.
Quizzes
Quiz 1: Why is the Greedy Coordinate Gradient (GCG) algorithm considered a “White-Box” attack, and why is this a limitation for red teaming commercial APIs?
GCG is a White-Box attack because it requires access to the model’s embedding matrix and the ability to compute gradients via backpropagation through the model’s layers. When red teaming a commercial API (like OpenAI’s or Anthropic’s), the attacker only has Black-Box access (text in, text out) and cannot extract the gradients necessary to compute token replacements.
Quiz 2: In the context of the MITRE ATLAS framework, how does AI red teaming differ fundamentally from the traditional MITRE ATT&CK framework?
MITRE ATT&CK focuses on lateral movement, privilege escalation, and infrastructure compromise (e.g., exploiting a server vulnerability). MITRE ATLAS focuses on the vulnerabilities inherent to the AI model’s behavior and data (e.g., prompt injection, model inversion, data poisoning). ATLAS assumes the infrastructure might be secure, but the model itself can still be manipulated via its inputs.
Quiz 3: During a PAIR (Prompt Automatic Iterative Refinement) attack, what specific role does the “Critic” model play that enables the optimization loop?
The Critic model evaluates the Target model’s response and provides a quantitative score (e.g., 1 to 10 on harmfulness) along with qualitative feedback explaining why the attack failed or succeeded. This feedback is passed back to the Attacker model, acting as a natural language “gradient” that guides the Attacker to refine and improve its next prompt.
Quiz 4: What is the primary advantage of framing red teaming as a Markov Decision Process (MDP) using Reinforcement Learning rather than a single-turn optimization?
Framing it as an MDP allows the attacker to execute multi-turn conversational attacks. Single-turn attacks are often easily caught by standard safety filters. An RL agent can learn long-horizon strategies—such as building conversational context, establishing a persona, and slowly introducing harmful concepts over multiple turns—which effectively degrades the target model’s safety guardrails over the length of the context window.
Quiz 5: What is the “Refusal Gap,” and why is it a negative consequence of overly aggressive adversarial training?
The Refusal Gap is the discrepancy between a model’s actual safety boundaries and its refusal behavior. Aggressive adversarial training can cause “over-refusal,” where the model becomes overly cautious and refuses completely benign, safe requests simply because they share structural similarities with known attacks (e.g., refusing to write a fictional story about a hacker).
References
- MITRE ATLAS (2025). Adversarial Threat Landscape for Artificial-Intelligence Systems. MITRE Corporation.
- Zou, A., et al. (2023). Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043.
- Chao, P., et al. (2023). Jailbreaking Black Box Large Language Models in Twenty Queries. arXiv:2310.08419.
- Chen, Y., Du, X., Zou, X., Zhao, C., Deng, H., Li, H., & Kuang, X. (2025). Refusal-Aware Red Teaming: Exposing Inconsistency in Safety Evaluations. ACL Anthology.