18.3 Hallucination Detection
In Chapter 18.2, we examined jailbreaks—scenarios where an attacker intentionally subverts a model’s alignment to elicit harmful behavior. However, Foundation Models possess a far more insidious failure mode that requires no adversarial input: they confidently fabricate information.
In human psychology, split-brain patients often exhibit confabulation—inventing plausible but entirely false narratives to explain actions their conscious brain did not initiate, genuinely believing their own fabrications. Large Language Models (LLMs) suffer from a mathematical equivalent. Because they are optimized to maximize the likelihood of the next token, they prioritize local fluency over global factual consistency. When they encounter a gap in their latent knowledge, they do not naturally pause or express doubt; they seamlessly extrapolate, generating hallucinations.
Detecting these hallucinations has evolved from simple post-hoc string matching into a rigorous engineering discipline. This chapter explores the state-of-the-art (SOTA) in hallucination taxonomy, probabilistic detection mechanisms, and architectural mitigation strategies for production environments.
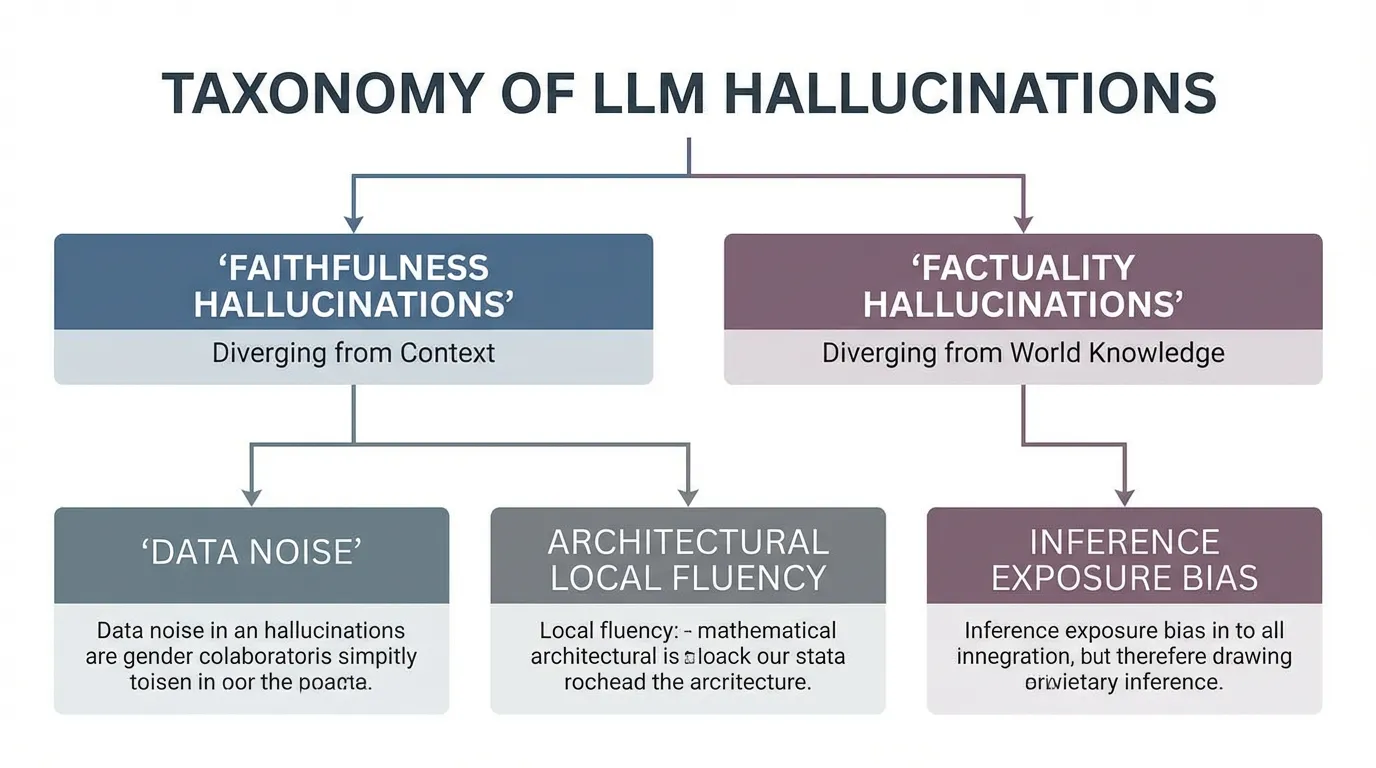
The Taxonomy of Hallucinations
According to a comprehensive 2025 survey on LLM failures [1], hallucinations are not a monolithic error type but a multi-stage failure in the model lifecycle. They are broadly categorized into two distinct axes:
- Faithfulness Hallucinations: The model’s output contradicts the specific context or prompt provided by the user. For instance, if a user provides a document stating “Revenue grew by 10%,” and the model summarizes it as “Revenue declined by 10%,” it has failed to remain faithful to the source.
- Factuality Hallucinations: The model’s output contradicts established real-world knowledge. This occurs when the model relies on its internal parametric memory and surfaces incorrect dates, non-existent entities, or fabricated scientific citations.
 Source: Generated by Gemini (Concept based on arXiv:2510.06265)
Source: Generated by Gemini (Concept based on arXiv:2510.06265)
Root Causes
The underlying causes of these fabrications span the entire training stack:
- Data-Level: Pre-training corpora are riddled with noise, contradictions, and knowledge cut-offs. When the data distribution is sparse for a specific entity, the model is forced to “guess.”
- Architecture-Level: The Transformer’s self-attention mechanism is inherently greedy. It optimizes for the most probable next token rather than the overall truth value of the completed sequence.
- Inference-Level (Exposure Bias): During auto-regressive decoding, early errors compound. If a model generates a slightly inaccurate token early in a sentence, the attention mechanism conditions all subsequent tokens on that error, dragging the model down a fabricated path.
State-of-the-Art Detection Mechanisms
Modern hallucination detection relies on quantifying the model’s epistemic uncertainty (what the model knows it doesn’t know) and semantic consistency.
Measuring Token-Level Uncertainty
The most direct signal of a potential hallucination lies in the model’s output logits. When a model is confident, the probability distribution over the vocabulary is sharp (a single token dominates). When the model is guessing, the distribution flattens, increasing the predictive entropy.
We can quantify this uncertainty using Shannon Entropy :
Where is the vocabulary, is the prompt, and are the previously generated tokens. High entropy at entities (names, dates, numbers) strongly correlates with factuality hallucinations.
Below is a PyTorch implementation for extracting and calculating token-level predictive entropy during a forward pass.
import torch
import torch.nn.functional as F
def compute_predictive_entropy(logits: torch.Tensor) -> torch.Tensor:
"""
Computes the predictive entropy of the next-token distribution.
Args:
logits (torch.Tensor): Raw logits from the model.
Shape: (batch_size, seq_len, vocab_size)
Returns:
torch.Tensor: Entropy values per token.
Shape: (batch_size, seq_len)
"""
# Convert logits to probabilities
probs = F.softmax(logits, dim=-1)
# Compute log probabilities (log_softmax is numerically stabler than torch.log(probs))
log_probs = F.log_softmax(logits, dim=-1)
# Calculate entropy: H(x) = -sum(p(x) * log(p(x)))
entropy = -torch.sum(probs * log_probs, dim=-1)
return entropy
# Example usage with dummy logits (Batch Size: 2, Seq Len: 10, Vocab: 32000)
dummy_logits = torch.randn(2, 10, 32000)
token_entropies = compute_predictive_entropy(dummy_logits)
# A sudden spike in entropy often precedes a hallucinated entity
print(f"Entropy sequence for Batch 0: {token_entropies.tolist()}")Semantic Entropy and Self-Consistency
Token-level entropy has a flaw: Lexical Equivalence. A model might have high entropy because it is deciding between “Paris,” “The capital of France,” and “The City of Light.” The token probabilities are split, but the semantic meaning is identical.
To solve this, researchers use Semantic Entropy [4] and frameworks like SelfCheckGPT [5]. The system samples multiple responses to the same prompt using a high temperature. It then uses a secondary model (a Natural Language Inference, or NLI, critic) to cluster the responses based on semantic equivalence (entailment).
If the model generates three wildly different answers (e.g., “1992,” “1995,” “1998”), the semantic entropy is high, indicating a hallucination. If it generates “1992,” “In the year 1992,” and “Nineteen ninety-two,” the semantic entropy is low, indicating factual confidence.
Interactive Semantic Entropy Visualizer
Use the interactive component below to see how an NLI critic clusters multiple sampled outputs to calculate semantic entropy and flag hallucinations.
The “Creativity Gap”: When Hallucination is a Feature
Not all deviations from ground truth are harmful. Recent findings from ACL 2025 [2] introduce a critical nuance regarding the “creativity vs. factuality” trade-off, particularly in decision-making and brainstorming tasks.
When evaluating models like Llama 3.1 and Gemma 2 on “Alternative Generation” tasks, researchers noticed that models frequently generated suggestions that did not align with human ground-truth data. Historically, this was penalized as a hallucination. However, human evaluators found many of these “hallucinated” alternatives to be highly valid and creative—sometimes surpassing human baselines.
To measure this, the researchers introduced two new metrics:
- Crowd Intersection: Measures how often the model’s generated alternatives overlap with the broader, uncurated pool of human ideas.
- Final Commit Intersection: Measures how often the model’s “hallucinated” ideas are actually adopted by human decision-makers in the final output.
The Engineering Takeaway: Hallucination detection must be context-aware. In a medical diagnostic system, strict RAG-grounded factuality is non-negotiable. In a creative writing or strategic brainstorming assistant, over-tuning the model to suppress all divergence (zero temperature, strict entailment) destroys its utility.
Production-Grade Mitigation Architecture
In production environments, detecting a hallucination after it has been generated is inefficient. Modern engineering focuses on architectural mitigation, primarily through advanced Retrieval-Augmented Generation (RAG) orchestration [3].
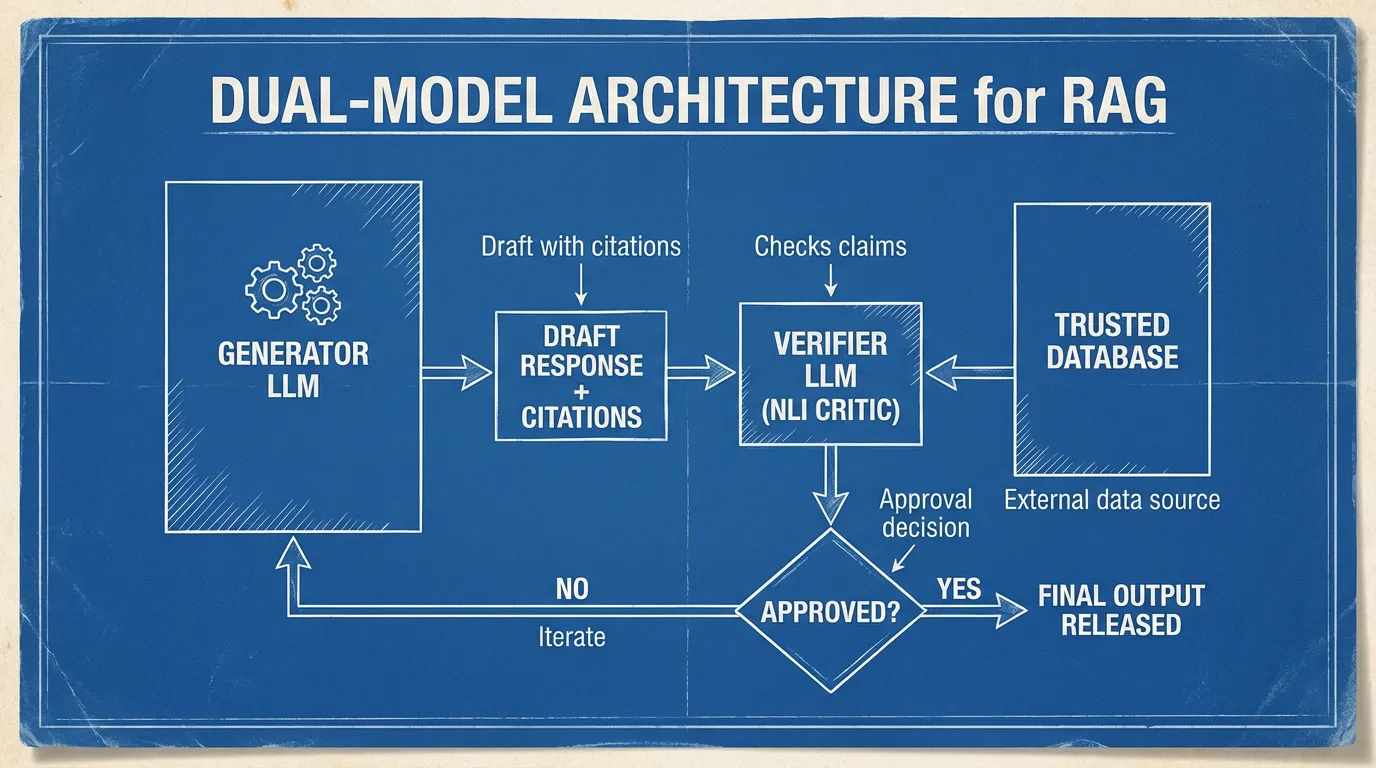
Dual-Model Architecture (Generator + Verifier)
Relying on a single model to both generate text and self-correct is mathematically flawed; the model is blind to its own latent gaps. Production systems utilize a Dual-Model Architecture:
- The Generator (Primary LLM): A massive frontier model (e.g., GPT-4, Claude 3.5) tasked with synthesizing retrieved context and drafting a response. It is explicitly prompted to provide Source Attribution (citations) for every atomic claim.
- The Verifier (NLI Critic): A smaller, highly specialized model (e.g., a fine-tuned DeBERTa-v3 or Llama-3-8B) that acts as a gatekeeper. It decomposes the Generator’s output into atomic claims and cross-references them against the retrieved documents. If a claim lacks entailment from the trusted database, the Verifier halts the output or forces a rewrite.
 Source: Generated by Gemini
Source: Generated by Gemini
Comparison of Detection Strategies
| Strategy | Mechanism | Pros | Cons |
|---|---|---|---|
| Logit Analysis | Calculates predictive entropy from output token probabilities. | Extremely fast; zero additional inference cost. | Prone to false positives due to lexical equivalence (synonyms). |
| Self-Consistency | Generates samples and checks for semantic overlap. | Highly accurate for factuality; captures true epistemic uncertainty. | Computationally expensive ( inference cost). |
| NLI Verification | Uses a critic model to check entailment against source docs. | Gold standard for RAG; ensures strict faithfulness. | Requires maintaining a separate, highly accurate critic model. |
Summary & Open Questions
Hallucination detection has matured from simple heuristics to rigorous probabilistic and architectural frameworks. We explored how token-level entropy reveals a model’s uncertainty, how semantic clustering solves the lexical equivalence problem, and how production systems use Dual-Model architectures to enforce factual grounding. Furthermore, we acknowledged the delicate balance between factual rigidity and creative divergence.
However, as models become more capable, their hallucinations become more subtle. A model might generate a perfectly logical, mathematically sound proof that rests on a single, fabricated foundational axiom.
- How do we detect hallucinations in complex reasoning tasks (like coding or advanced mathematics) where external fact-checking databases do not exist?
- If a model is significantly smarter than its human operator, how can the human verify the model’s output without blindly trusting it?
This brings us to the ultimate challenge of alignment and safety. In Chapter 18.4: Scalable Oversight, we will explore how to supervise and evaluate AI systems whose intelligence surpasses our own ability to easily verify their work.
Quizzes
Quiz 1: What is the fundamental difference between a Faithfulness Hallucination and a Factuality Hallucination?
A Faithfulness Hallucination occurs when the model contradicts the specific context or prompt provided by the user (e.g., misinterpreting a provided RAG document). A Factuality Hallucination occurs when the model contradicts established real-world knowledge based on its own flawed parametric memory.
Quiz 2: Why is token-level predictive entropy alone sometimes an unreliable metric for detecting factual hallucinations?
Token-level entropy suffers from the “Lexical Equivalence” problem. A model might be highly confident in a fact but uncertain about exactly which synonym to use (e.g., “Paris” vs. “The capital of France”). This splits the token probabilities, causing high entropy even though the underlying semantic knowledge is robust and factual.
Quiz 3: How does the “Dual-Model Architecture” address the inherent limitations of a single LLM in production RAG systems?
A single model struggles to self-correct because it is blind to its own latent knowledge gaps. A Dual-Model Architecture separates concerns: a large Generator drafts the response, while a smaller, specialized Verifier (NLI Critic) objectively cross-references the Generator’s atomic claims against the trusted database, ensuring strict entailment before releasing the output.
Quiz 4: Based on the ACL 2025 findings on the “Creativity Gap,” why might aggressive hallucination suppression be detrimental in certain applications?
In brainstorming or strategic decision-making tasks, what strict metrics classify as a “hallucination” (divergence from human ground-truth baselines) is often perceived by users as highly creative and valid alternative generation. Suppressing this divergence entirely limits the model’s utility as an ideation partner.
Quiz 5: Formalize the explicit logical sequence for Natural Language Inference (NLI) entailment boundaries when evaluating atomic claims against retrieved documents . Define the explicit soft-logits thresholds for Contradiction vs Entailment.
NLI verification is formalized as a multi-class sequence: . Explicit soft-logits boundaries are set: Entailment flags if (typically ). Contradiction triggers reject boundaries when . When Neutral soft-logits sit dominant, the claim lacks explicit grounding but does not actively contradict, allowing engineering pipelines to selectively inject neutral-warning deterministic prefixes.
References
- Zhang, Y., et al. (2025). Large Language Models Hallucination: A Comprehensive Survey. arXiv:2510.06265.
- Chen, L., et al. (2025). The Creativity Gap: Re-evaluating Hallucination in Decision-Support LLMs. Findings of the Association for Computational Linguistics: EMNLP 2025.
- Blockchain Council. (2025). Production-Grade Retrieval-Augmented Generation: A Comprehensive Guide.
- Farquhar, S., et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017), 625-630.
- Manakul, P., et al. (2023). SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. arXiv:2303.08896.