5.5 Case Study: Teardown of SOTA MoE Architectures
The transition from dense monolithic networks to sparse Mixture of Experts (MoE) is not merely a hardware optimization; it is a fundamental shift in how we conceptualize model capacity. In the dense paradigm, every parameter is multiplied by every token, coupling computational cost directly to model knowledge. MoE shatters this linearity. By decoupling the parameter count from the floating-point operations (FLOPs) required per token, MoE architectures allow models to absorb vast amounts of world knowledge while maintaining the inference latency of a much smaller network.
In this case study, we will perform a technical teardown of four seminal MoE architectures: Mixtral 8x7B, DBRX, Grok-1, and DeepSeek-V3. Rather than just listing their specifications, we will dissect the specific engineering trade-offs and routing innovations each team made to push the Pareto frontier of scale and efficiency.
1. Mixtral 8x7B: The Open-Source MoE Catalyst
Released in late 2023 by Mistral AI, Mixtral 8x7B [1] was the catalyst that brought MoE architectures to the open-source masses. It shattered the illusion that MoE was exclusively the domain of trillion-parameter hyperscaler models like GPT-4.
The “8x7B” Misnomer
The name “8x7B” is a brilliant marketing move, but a technical misnomer. A common misconception is that Mixtral is an ensemble of eight independent 7-billion-parameter models, which would total 56 billion parameters. In reality, Mixtral has 47B total parameters, with only 13B active during the forward pass for any given token.
Why 47B? In the Transformer architecture, the self-attention mechanism and the token embeddings are shared across all experts. Only the Feed-Forward Network (FFN) layers are replicated. If represents the attention parameters and represents the FFN parameters of a dense 7B model, the total parameter count for Mixtral is roughly:
Routing Mechanism
Mixtral employs a standard Top-2 routing mechanism out of 8 experts (). For a given input state , the router computes a gating vector using a softmax over the top-2 logits. The output of the MoE layer is the weighted sum of the two selected experts:
By activating only two experts per token, Mixtral achieves the inference speed of a ~12B parameter model while leveraging the knowledge capacity of a 47B parameter model. This proved that sparse MoE could be trained efficiently and deployed on consumer hardware (when quantized), democratizing the architecture.
2. DBRX: The Power of Fine-Grained Experts
While Mixtral proved the viability of coarse-grained MoE, Databricks’ DBRX took a different path by introducing a fine-grained MoE architecture based on the MegaBlocks framework [2].
The Combinatorial Explosion
DBRX features 132B total parameters with 36B active parameters. Instead of using 8 large experts and selecting 2, DBRX uses 16 smaller experts and selects 4 ().
While both Mixtral and DBRX activate 25% of their FFN parameters, the mathematical implications for representation power are vastly different. The number of possible routing combinations (expert paths) a token can take through a single layer is determined by the binomial coefficient :
- Mixtral (8 choose 2): possible paths.
- DBRX (16 choose 4): possible paths.
By using more, smaller experts, DBRX provides 65 times more routing combinations. This fine-grained specialization allows the model to mix and match concepts with much higher granularity, significantly improving model quality and generalization without increasing the active parameter count.
Dropless Routing (MegaBlocks)
Traditional MoE implementations enforce a strict “capacity factor” for each expert to maintain static tensor shapes for GPU operations. If an expert receives too many tokens, the excess tokens are simply dropped (passed through via residual connection without FFN processing), degrading performance.
DBRX utilizes MegaBlocks, which reformulates MoE computation using block-sparse matrix multiplications. This allows for dynamically sized experts, completely eliminating token dropping (“dropless routing”) and avoiding the wasted compute associated with padding under-utilized experts.
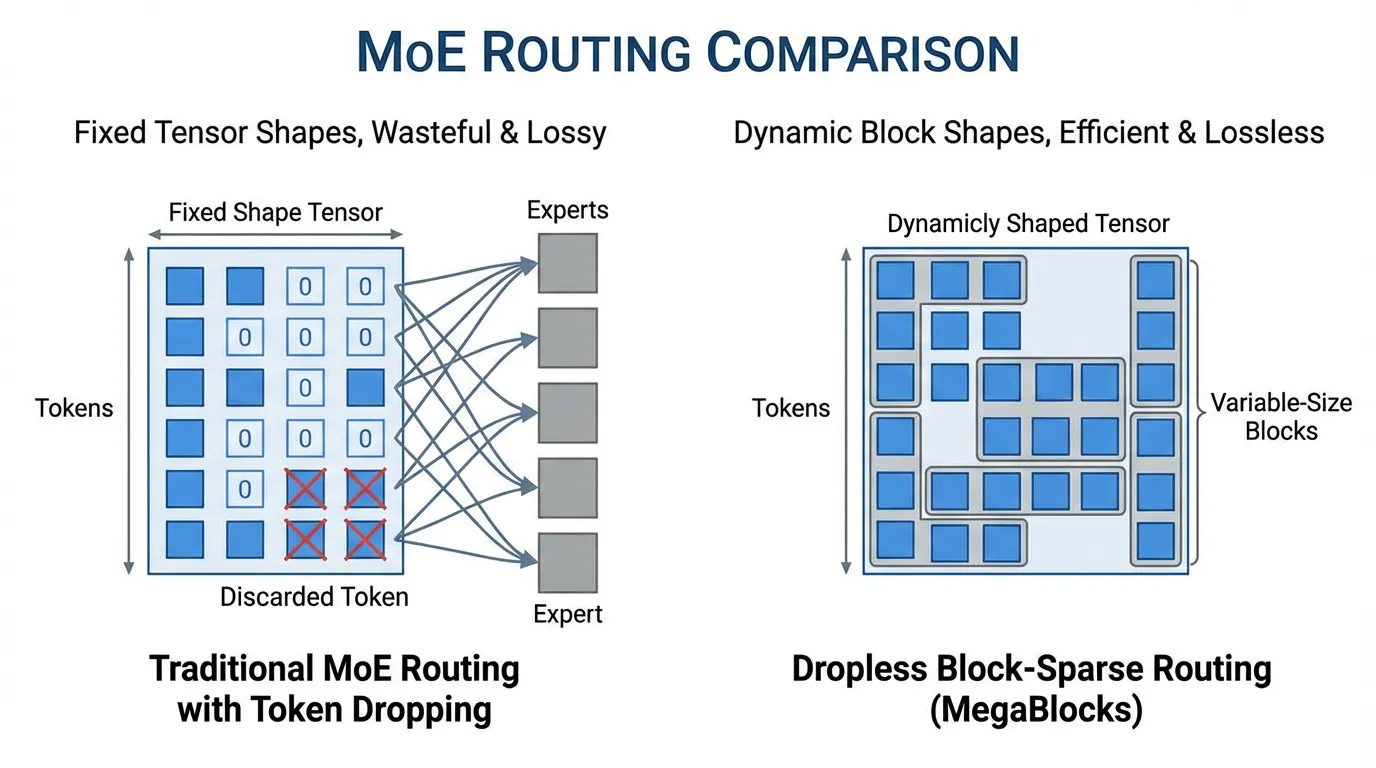 Source: Generated by Gemini
Source: Generated by Gemini
3. Grok-1: Brute Force Scaling
Developed by xAI, Grok-1 [3] is a testament to brute-force scaling. At the time of its open release, it was one of the largest open-source models in existence, boasting a massive 314B total parameters.
Like Mixtral, Grok-1 uses a Top-2 out of 8 routing strategy. However, because the base model is so large, the active parameter count per token is roughly 78B. This means that even the sparse forward pass of Grok-1 is larger than the entire dense Llama-2 70B model.
The primary engineering challenge with Grok-1 is not FLOPs, but memory bandwidth. To run inference on Grok-1 in 16-bit precision requires over 600GB of VRAM, necessitating an 8-way GPU node (e.g., 8x H100 or 8x MI300X) purely to hold the weights. Grok-1 highlights the inevitable infrastructure wall of MoE: while compute (FLOPs) remains low, memory capacity requirements scale linearly with total parameters.
4. DeepSeek-V3: The Pinnacle of Efficiency
Released in late 2024, DeepSeek-V3 [4] represents a masterclass in MoE engineering. It achieves performance comparable to closed-source frontier models (like GPT-4o and Claude 3.5 Sonnet) while requiring only 2.78 million H800 GPU hours for its entire pre-training run—a fraction of the compute used by its peers.
DeepSeek-V3 features 671B total parameters but only 37B active parameters per token. This extreme sparsity (activating ~5.5% of parameters) is achieved through several radical architectural innovations.
DeepSeekMoE: Shared + Fine-Grained Routed Experts
Instead of a standard routing pool, DeepSeek-V3 splits its FFN into two distinct types of experts:
- Shared Experts: 1 expert that is always activated for every token. This expert captures common linguistic structures and general knowledge, acting as the dense backbone of the network.
- Routed Experts: 256 highly specialized, fine-grained experts. The router selects up to 8 of these per token.
This decoupling prevents the routing collapse often seen in standard MoEs, where early layers struggle to route tokens because all experts are trying to learn basic grammar simultaneously.
Auxiliary-Loss-Free Load Balancing
In standard MoE training, an auxiliary loss function () is added to the main language modeling loss to force the router to distribute tokens evenly across experts. Without it, the network falls into a “rich get richer” loop (routing collapse). However, this auxiliary loss creates competing gradients: the model is penalized for sending a token to the best expert if that expert is currently overloaded.
DeepSeek-V3 pioneers an Auxiliary-Loss-Free strategy. Instead of modifying the loss function, they dynamically adjust a bias term added directly to the routing logits during the forward pass.
If an expert is overloaded, its bias is decreased. If it is starved, its bias is increased. This ensures load balancing without contaminating the gradient of the primary language modeling task.
Implementing Auxiliary-Free Routing
Below is a PyTorch implementation demonstrating the core concept of DeepSeek-V3’s dynamic bias routing. Notice how the bias is applied only for the Top-K selection, while the actual gating weights used for the FFN combination are derived from the unbiased logits.
import torch
import torch.nn as nn
import torch.nn.functional as F
class DeepSeekAuxFreeRouter(nn.Module):
def __init__(self, d_model: int, num_routed_experts: int, top_k: int):
super().__init__()
# The router network (no bias in the linear layer itself)
self.gate = nn.Linear(d_model, num_routed_experts, bias=False)
self.top_k = top_k
# The dynamic bias term for load balancing (not updated via backprop)
self.register_buffer("expert_bias", torch.zeros(num_routed_experts))
def forward(self, x: torch.Tensor):
# x shape: [batch_size, seq_len, d_model]
logits = self.gate(x) # [B, S, E]
# 1. Add the dynamic bias for routing decisions ONLY
routing_logits = logits + self.expert_bias
# 2. Select top-k experts based on the BIASED logits
topk_logits, topk_indices = torch.topk(routing_logits, self.top_k, dim=-1)
# 3. Compute gating weights using the UNBIASED logits
# DeepSeek uses sigmoid for affine combination rather than softmax
# This allows the total sum of weights to be unconstrained (not strictly 1.0)
unbiased_selected_logits = logits.gather(-1, topk_indices)
gate_weights = torch.sigmoid(unbiased_selected_logits)
# Normalize weights (optional, depending on specific DeepSeek implementation details)
gate_weights = gate_weights / gate_weights.sum(dim=-1, keepdim=True)
return gate_weights, topk_indices
@torch.no_grad()
def update_bias(self, expert_load: torch.Tensor, target_load: torch.Tensor, step_size: float = 0.001):
"""
Called at the end of a training step.
expert_load: The actual number of tokens routed to each expert in this batch.
target_load: The ideal uniform distribution of tokens.
"""
# If load > target, diff is negative -> bias decreases.
# If load < target, diff is positive -> bias increases.
load_diff = target_load - expert_load
# DeepSeek uses a sign-based or proportional update rule
self.expert_bias += step_size * torch.sign(load_diff)By removing the auxiliary loss, DeepSeek-V3 achieves a purer signal for the next-token prediction task, which is a major factor in its state-of-the-art performance on reasoning and mathematics benchmarks.
5. Architectural Comparison
To synthesize the differences, let’s look at a comparative matrix of these models alongside a dense baseline (Llama-3 70B).
| Model | Architecture Type | Total Params | Active Params | Experts () | Top-K () | Routing Strategy |
|---|---|---|---|---|---|---|
| Llama-3 70B | Dense | 70B | 70B | N/A | N/A | N/A |
| Mixtral 8x7B | Coarse MoE | 47B | 13B | 8 | 2 | Standard Softmax |
| DBRX | Fine-Grained MoE | 132B | 36B | 16 | 4 | Dropless (MegaBlocks) |
| Grok-1 | Coarse MoE | 314B | ~78B | 8 | 2 | Standard Softmax |
| DeepSeek-V3 | Ultra-Fine MoE | 671B | 37B | 256 (+1 Shared) | 8 | Aux-Loss-Free Bias |
Observation: The industry trend is clear. Models are moving from coarse-grained experts (8 choose 2) toward extreme fine-grained sparsity (256 choose 8). Total parameter counts are skyrocketing to capture world knowledge, while active parameter counts are tightly constrained to maintain inference speed and batch processing efficiency.
6. Summary & Next Steps
The evolution of MoE architectures from Mixtral to DeepSeek-V3 demonstrates that scaling intelligence is no longer just about stacking more layers; it is about routing efficiency and sparsity. We have seen how fine-grained experts increase combinatorial capacity, how dropless routing maximizes hardware utilization, and how auxiliary-loss-free strategies protect the purity of the learning signal.
However, designing the architecture is only half the battle. Training a 671B parameter model with 256 experts introduces catastrophic system-level challenges. How do we feed 15 trillion tokens into these models without the GPUs idling? How do we handle the massive cross-node communication overhead when tokens need to be sent to experts residing on entirely different servers?
In the next chapter, Chapter 6: Foundation Model Pre-training, we will descend into the infrastructure layer. We will explore the massive data engineering pipelines, the tokenization science, and the extreme networking (NVLink/InfiniBand) required to keep these sparse leviathans fed and stable during months of continuous training.
Quizzes
Quiz 1: Why is Mixtral 8x7B’s total parameter count 47B instead of 56B?
Mixtral does not replicate the entire 7B model eight times. Only the FFN layers are duplicated across the experts, while the attention weights and token embeddings remain shared. Because the FFN accounts for a large share of a dense Transformer’s parameters, repeating only that part yields roughly 47B total parameters rather than 56B.
Quiz 2: What is the primary advantage of DBRX’s routing configuration?
The main advantage is the combinatorial explosion of routing paths. Mixtral has possible expert combinations per layer, while DBRX has . That much larger routing space lets DBRX mix finer-grained experts more flexibly, increasing representational capacity without increasing active compute per token.
Quiz 3: Why is DeepSeek-V3’s dynamic bias trick better than the standard auxiliary loss?
The standard auxiliary loss adds a balancing penalty directly to the objective, which creates a gradient conflict with the main language-modeling loss. If Expert A is the best expert for a token but is temporarily overloaded, the auxiliary loss can push the model toward a worse expert just to satisfy the balancing term. DeepSeek’s dynamic bias fixes load balancing mechanically in the forward pass, while keeping the bias detached from backpropagation so the semantic learning signal stays clean.
Quiz 4: What happens when an expert exceeds its capacity factor, and how does MegaBlocks fix it?
In traditional MoE implementations, static tensor shapes are required for efficient GPU execution. When an expert exceeds its capacity, the extra tokens are dropped and bypass the FFN entirely, which hurts quality. If an expert receives too few tokens, the unused slots are padded, wasting compute. MegaBlocks replaces that rigid scheme with block-sparse matrix multiplications so the computation blocks match the routed tokens exactly, avoiding both dropping and padding.
References
- Jiang, A. Q., et al. (2024). Mixtral of Experts. arXiv preprint. arXiv:2401.04088.
- Gale, T., et al. (2022). MegaBlocks: Efficient Routing for Mixture-of-Experts. arXiv preprint. arXiv:2211.15841.
- xAI. (2024). “Open Release of Grok-1.” “xAI Blog”. Link.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv:2412.19437.