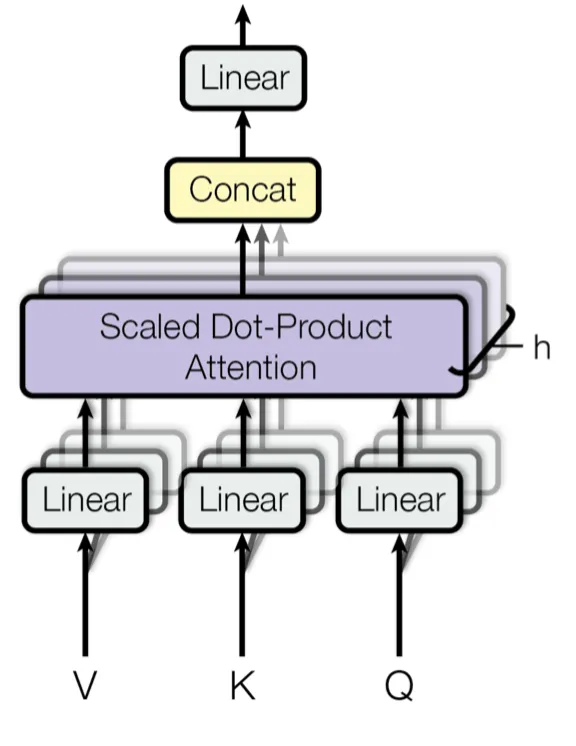
3.2 Multi-head Attention (MHA)
While Self-Attention is powerful, applying it once (Single-Head) limits the model’s ability to focus on different types of relationships simultaneously. Multi-Head Attention (MHA) solves this by running multiple attention mechanisms in parallel.
Let’s understand this through a metaphor.
The Metaphor: The Committee of Experts
Imagine you are analyzing a complex legal document.
- Single-Head Attention is like having one general researcher read the document. They might do a good job, but they can only focus on one aspect at a time (e.g., the general meaning).
- Multi-Head Attention is like hiring a committee of experts:
- Expert 1 focuses on the legal terminology.
- Expert 2 focuses on the financial implications.
- Expert 3 focuses on the historical context.
They all read the same document simultaneously but attend to different aspects. In the end, they combine their findings to give a much richer analysis.
In MHA, each “head” learns to attend to different types of relationships (e.g., grammar, coreference, factual links).
Why Multi-Head? (Representation Subspaces)
To understand the benefit of Multi-Head Attention, consider the word “bank”. It can mean a financial institution or the side of a river.
- In a single-head attention mechanism, the model must create a single attention distribution for “bank”. If it needs to capture both the financial context (relating to “money”) and the syntactic context (relating to the preceding article “the”), it has to compromise.
- With Multi-Head Attention, one head can focus on the semantic relationship (bank money), while another head can focus on the syntactic relationship (bank the).
By projecting the -dimensional embeddings into smaller subspaces of dimension , each head can specialize in finding specific types of patterns without interference from other patterns. This is analogous to how CNNs use multiple filters to detect different visual features (e.g., edges, textures).
The Mathematics of Multi-Head Attention
Instead of performing a single attention function with -dimensional keys, values, and queries, MHA linearly projects the queries, keys, and values times with different, learned linear projections to and dimensions, respectively.
Where:
And the projections are parameter matrices:
Typically, we use parallel attention heads. For each of these we use .
PyTorch Implementation
Here is how you implement Multi-Head Attention in PyTorch. This involves projecting the inputs, splitting them into multiple heads, applying attention, and then concatenating the results.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# Linear projections for Q, K, V
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# Output projection
self.w_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. Linear projections
Q = self.w_q(q)
K = self.w_k(k)
V = self.w_v(v)
# 2. Split into heads
# Shape change: (batch, seq_len, d_model) -> (batch, seq_len, num_heads, d_k) -> (batch, num_heads, seq_len, d_k)
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 3. Apply Scaled Dot-Product Attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(weights, V)
# 4. Concatenate heads
# Shape change: (batch, num_heads, seq_len, d_k) -> (batch, seq_len, num_heads, d_k) -> (batch, seq_len, d_model)
concat_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 5. Output projection
output = self.w_o(concat_output)
return output, weights
# Example usage
mha = MultiHeadAttention(d_model=64, num_heads=8)
x = torch.randn(2, 10, 64) # Batch of 2, sequence length 10, d_model 64
output, weights = mha(x, x, x)
print("Output Shape:", output.shape)
print("Attention Weights Shape:", weights.shape)Example: Diverse Perspectives
Visualize how two different heads might attend to the sentence “The bank was full of money.”
- Head 1 might learn to associate “bank” with “money” (financial context).
- Head 2 might learn to associate “bank” with “river” (if the context were different, but here it’s money).
Select a head to see its simulated attention pattern for the word “bank”.
Quizzes
Quiz 1: Why not just use one large attention head instead of multiple small ones?
Multiple heads allow the model to attend to information from different representation subspaces at different positions. A single large head can only compute one set of attention weights, forcing it to average out different types of relationships, which can be less expressive.
Quiz 2: What is the purpose of the output projection in MHA?
After concatenating the outputs from all heads, the result has the dimension (which is typically equal to ). The output projection is a learned linear transformation that mixes the information from all heads and projects it back to the space, allowing the network to use the combined information effectively.
Quiz 3: If and we have heads, what is the dimension of for each head?
Typically, we set . So for each head, the dimension would be .
Quiz 4: How does the computational cost of Multi-Head Attention compare to Single-Head Attention with the same total dimension?
Due to the reduced dimension of each head (), the total computational cost of Multi-Head Attention is similar to that of Single-Head Attention with full dimensionality. The operations can be effectively batched and parallelized on GPUs.
Quiz 5: What would happen if we didn’t use the output projection after concatenating the heads?
Without the output projection , the model would just be concatenating independent features from different heads without learning how to combine or mix them. allows the model to learn interactions across different heads.
Quiz 6: Formally prove why the dot product in self-attention has a variance of under the assumption that the components of and are independent random variables with mean 0 and variance 1, and explain how the scaling factor restores the variance to 1.
Let be vectors whose components are independent random variables with and . The dot product is . Since and are independent, . The variance of the product of independent variables is . Since the components are independent, the variance of the sum is the sum of the variances: . By dividing by , the variance becomes . This scaling prevents the softmax from saturating into regions with extremely small gradients for large dimensions.
References
- Vaswani, A., et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). arXiv:1706.03762.