14.1 From Lexical to Semantic Search
In Chapter 13, we explored how to make Large Language Models smaller and faster through quantization and compression. While these techniques allow us to run powerful models on limited hardware, they do not solve a fundamental limitation of all foundation models: static parametric knowledge.
A model’s knowledge is frozen at the point of its training cut-off. It cannot answer questions about events after that date, nor can it access your private data or proprietary documents.
To bridge this gap, we need Retrieval-Augmented Generation (RAG). Instead of trying to bake all the world’s knowledge into the model’s parameters (which is expensive and leads to hallucinations), RAG allows the model to dynamically search an external database for relevant information at query time.
This chapter marks the transition from optimizing the model itself to building the retrieval infrastructure around it. We start by understanding the fundamental shift from keyword matching to meaning matching.
In the early days of information retrieval, finding relevant documents relied almost entirely on Lexical Search (keyword search). While this approach powered the first generation of search engines and database queries, it suffers from fundamental limitations when applied to modern RAG systems. To build systems that truly understand user intent, we must transition from searching for words to searching for meaning.
This sub-chapter explains why vector embeddings are necessary, compares lexical and semantic search with an interactive demonstration, and explores advanced chunking strategies to prepare data for retrieval.
1. The Limits of Keyword Search
Lexical search operates on the principle of exact or fuzzy string matching. Algorithms like TF-IDF and BM25 count term frequencies and inverse document frequencies to rank documents. While highly optimized and fast, they fail in several critical scenarios:
A. The Synonym Problem (Vocabulary Mismatch)
If a user searches for “automobile” but the source document uses the word “car,” a strict lexical search will fail to connect them despite their identical meaning. This is known as vocabulary mismatch.
B. Polysemy (Context Blindness)
The word “bank” can mean a financial institution or the side of a river. Lexical search cannot distinguish between these meanings without additional context words, often leading to irrelevant results.
C. Cross-Lingual Limitations
Keyword search is strictly bound to the language of the query. A search in English cannot retrieve a relevant document written in Korean or Spanish, even if the content is exactly what the user needs.
D. The Solution: Vector Embeddings
To overcome these limits, we represent text as high-dimensional vectors where geometric distance corresponds to semantic similarity. An embedding model (like a fine-tuned BERT or a modern contrastive model) maps the concept of “automobile” and “car” to nearby points in the vector space, solving the synonym problem and enabling cross-lingual retrieval.
2. Interactive Concept: Lexical vs. Semantic Search
To understand the trade-offs, let’s look at a conceptual diagram and then interact with the visualizer below. We have a small database of documents covering various topics.
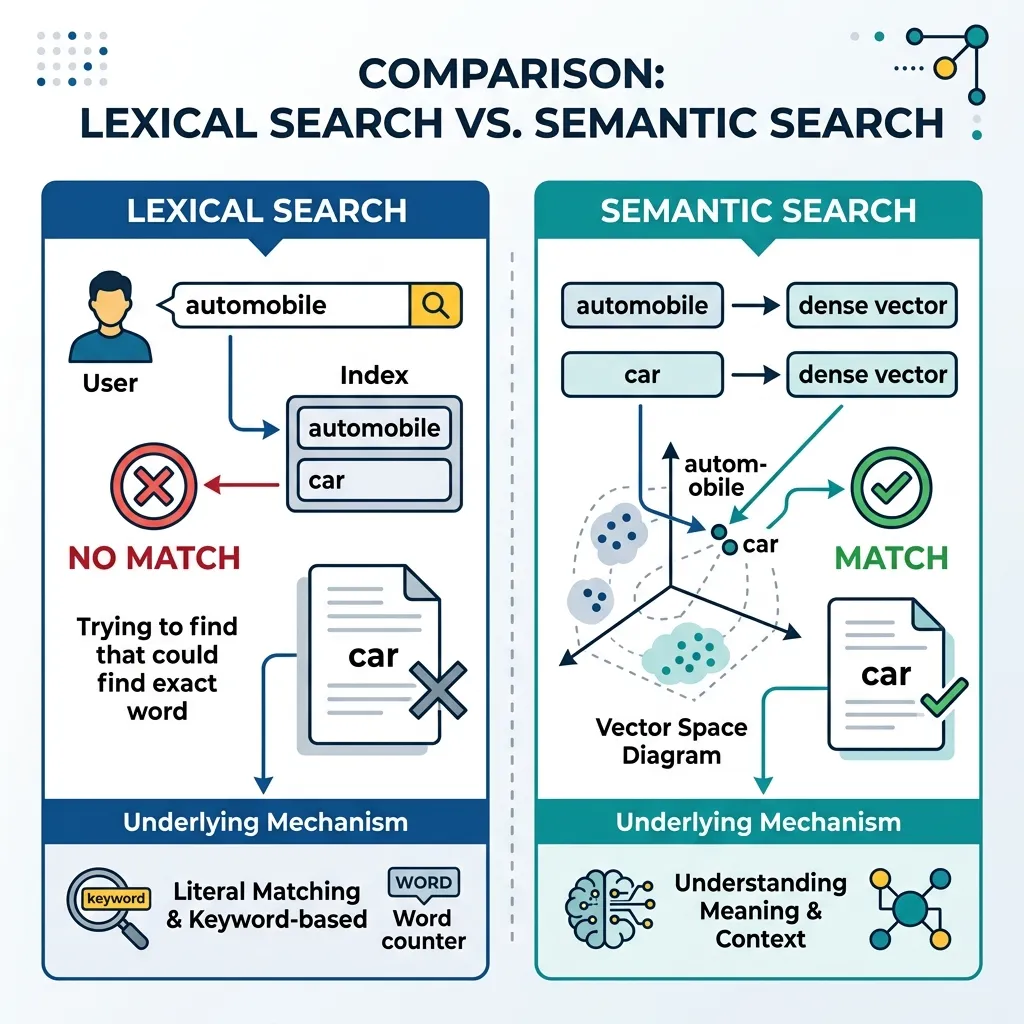
Try searching for concepts not explicitly mentioned in the text (e.g., searching for “puppy” when the text says “young dog”) to see how semantic search shines, and observe where keyword search might still be necessary (e.g., for specific product codes).
Semantic vs. Keyword Search
Try the preset queries to see the difference in behavior.
💡 Observations
- Search for "flat tire": Keyword search fails (vocabulary mismatch), but Semantic search finds both English and Korean documents (cross-lingual).
- Search for "XJ-992-B": Keyword search finds it perfectly. Semantic search gives low scores because it struggles with specific rare tokens like product codes.
The Keyword Stronghold: Precision on Specifics
As demonstrated above, semantic search is not a silver bullet. It tends to “blur” highly specific tokens like serial numbers, part codes, or rare proper nouns into general categories. For example, searching for Err-404 might retrieve documents about “web errors” in general rather than the specific log entry containing that exact string.
This is why enterprise RAG systems almost always employ Hybrid Search (combining both methods), which we will cover in sub-chapter 14.3.
3. Advanced Chunking Strategies
Before we can embed text and store it in a vector database, we must break large documents into smaller, coherent pieces called chunks. The way we chunk data dramatically impacts retrieval quality.
A. Naive (Fixed-Size) Chunking
The simplest approach is to split text into chunks of a fixed number of tokens (e.g., 256 tokens) with a small overlap (e.g., 20 tokens) to prevent cutting sentences in half.
- Pros: Simple to implement, predictable compute cost.
- Cons: Often breaks semantic coherence, splitting a paragraph or a list across two chunks, leading to loss of context.
B. Hierarchical Chunking
Instead of treating all chunks equally, hierarchical chunking maintains the document structure.
- Summary Chunk: A high-level summary of a large section (e.g., a whole chapter).
- Detail Chunks: Smaller chunks containing the actual text of that section.
- Retrieval can first search the summary chunks to identify the relevant section, and then narrow down to the detail chunks, reducing search space and improving precision.
C. Parent-Child (Small-to-Large) Chunking
This is one of the most effective strategies for RAG.
- The Problem: Small chunks are better for precise vector search (less noise), but large chunks provide better context for the LLM to generate an answer.
- The Solution: We break the document into small child chunks (e.g., 50 tokens) for retrieval. Each child chunk is linked to a larger parent chunk (e.g., 500 tokens). When the system retrieves a highly relevant child chunk, it actually feeds the corresponding parent chunk to the LLM.
4. The Mathematics of Semantic Space (InfoNCE and Matryoshka)
To understand how models create these semantic spaces, we must look at how they are trained. Modern dense retrievers are typically trained using Contrastive Learning.
Contrastive Learning and InfoNCE Loss
The goal of contrastive learning is to learn an embedding space where similar items are close together and dissimilar items are far apart. In RAG, this means a query should be close to its relevant document (positive sample) and far from other non-relevant documents (negative samples).
The standard loss function for this is InfoNCE (Information Noise Contrastive Estimation):
Here:
- is a similarity metric, usually dot product or cosine similarity.
- is a temperature parameter that scales the distribution.
- The formula essentially calculates the probability that the positive document is correctly identified among a set of negative documents, framed as a multi-class classification problem.
Matryoshka Representation Learning (MRL)
In large-scale systems, storing high-dimensional vectors (e.g., 768 or 1536 dimensions) for billions of documents becomes extremely expensive in terms of memory and search latency.
Matryoshka Representation Learning (MRL) [1] solves this by training the model to pack information into the early dimensions of the vector. Inspired by Russian nesting dolls (Matryoshka), MRL ensures that the first dimensions (e.g., 64, 128, 256) are independently capable of high-quality retrieval.
Developers can truncate a 768-dimensional vector to just 128 dimensions. This reduces storage and compute costs by while retaining up to 95% of the original retrieval performance. This “elastic” embedding capability is crucial for optimizing cost-performance trade-offs in production RAG pipelines.
Quizzes
Quiz 1: A user searches for “How to fix a punctured tire?” in a system using strict lexical search. The database contains a document titled “Repairing a flat tire”. Will the lexical search find it? Why or why not?
It is unlikely to rank highly unless fuzzy matching or stemming is aggressively applied. “Punctured” and “flat” are synonyms but share no common letters, and “tire” is the only matching keyword. Semantic search would easily identify the shared intent.
Quiz 2: Why does Parent-Child chunking use small chunks for retrieval but large chunks for generation?
Small chunks have a higher signal-to-noise ratio for vector embeddings, making retrieval more accurate. However, an LLM needs the surrounding context to generate a coherent and accurate answer, which the larger parent chunk provides.
Quiz 3: Formulate the mathematical hybrid similarity score that explicitly combines BM25 lexical scoring with Dense Passage Retrieval (DPR) dot-product similarity. Why is normalization required?
The hybrid score is formulated as a convex combination of normalized scores: , where is the balancing hyperparameter. Because BM25 is unbounded () while dot products are bounded by vector magnitudes, explicit normalization (like Min-Max pool scaling) is mathematically required to prevent one score distribution from flat-lining or hijacking the fused relevance ranking.
References
- Kusupati, A., et al. (2022). Matryoshka Representation Learning. arXiv:2205.13147.