13.4 Knowledge Distillation
If quantization is like shaving weight off a suitcase, Knowledge Distillation (KD) is like repacking the contents into a smaller bag. Instead of keeping the original model architecture and merely compressing its weights, KD trains a new, smaller student model to imitate a larger teacher.
That distinction matters in practice. Quantization and sparsification are constrained by the shape of the original network. Distillation is freer: the student can have different width, depth, and even a different architecture, as long as it learns the behavior we care about.
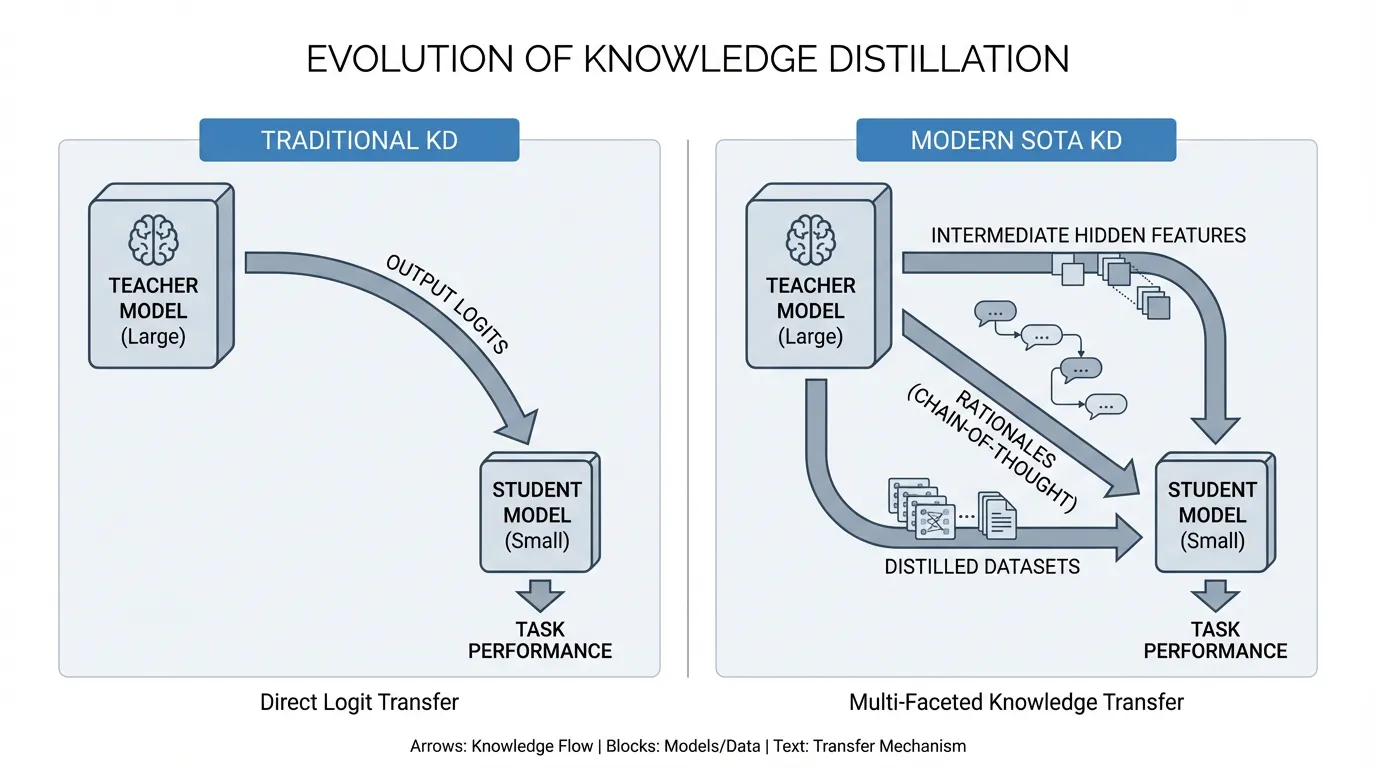
In the LLM era, KD has also become more ambitious. The goal is no longer just to copy output probabilities. Engineers increasingly try to transfer reasoning traces, hidden-state structure, and decoding behavior into smaller models that are cheap enough to serve widely.
1. The Evolution: From Logits to Rationales
Historically, KD relied on Logit Matching. Introduced by Geoffrey Hinton and colleagues in 2015 [1], the core idea was that the raw output logits of a teacher model contain “dark knowledge”—the relative probabilities of incorrect answers that reveal how the model generalizes.
By applying a high Temperature () to the Softmax function, the sharp probability distribution is smoothed out, forcing the student to learn these subtle relationships via Kullback-Leibler (KL) Divergence:
While highly effective for classification, logit-only KD is often not enough for harder generative work. In LLMs, matching the final token distribution can teach the student what answer tends to appear, but not necessarily how the teacher arrived there. That is one reason small students sometimes mimic style well yet still lag on reasoning-heavy tasks.
Richer Supervision in Modern KD
To reduce that gap, recent work adds supervision beyond final logits:
- Rationale-Based Distillation: The teacher provides intermediate reasoning or step-by-step traces, not just the final answer [2].
- Feature-Based Alignment: The student is nudged to match some internal hidden-state structure of the teacher, not just its output layer.
These methods do not magically guarantee “compressed reasoning,” but they often transfer more useful behavior than output matching alone.
2. Distribution Calibration for Generative Models: Forward KL vs Reverse KL
In knowledge distillation for autoregressive models that generate tokens sequentially, one of the most critical mathematical decisions is the direction of the Divergence function. Traditional knowledge distillation minimizes the Forward KL Divergence between the teacher distribution and the student distribution .
- Forward KL (Mean-seeking): This is the classic choice. It encourages the student to cover the support of the teacher distribution. That can be helpful when broad coverage matters, but it can also spread probability mass too widely when the student is much smaller than the teacher.
- Reverse KL (Mode-seeking): Work such as MiniLLM argues that for autoregressive generation, Reverse KL Divergence can be a better fit in some settings [3]. It encourages the student to commit more strongly to modes the teacher itself prefers, which can improve fluency and reduce diffuse, low-confidence generations.
The key lesson is not that one direction is universally superior. It is that the divergence choice changes the student’s behavior, and generative KD often benefits from treating this as a design decision rather than a default.
3. On-Policy Distillation: Learning from Student’s Mistakes
Distillation methods relying on fixed offline datasets (Off-policy) suffer from a fatal problem during text generation called Exposure Bias. During training, the student only sees perfect text trajectories generated by the teacher model. However, during actual inference, if the student model accidentally generates even a single token differently, the subsequent trajectory becomes an unknown territory (Out-of-Distribution) not present in the training data, causing the output quality to collapse.
One response is On-Policy Distillation. Instead of training only on teacher-generated trajectories, methods such as Generalized Knowledge Distillation (GKD) ask the teacher to score sequences that the student itself produced [4]. That way, the teacher is not only showing the “ideal path.” It is also correcting the student in the situations the student is likely to create at inference time.
This matters operationally because deployed models do not fail on pristine examples. They fail after a slightly wrong turn, when the next token must be chosen from a bad local state.
4. Bridging Architectural Heterogeneity
A practical advantage of KD is that the student does not have to be a miniature copy of the teacher. You can distill from a larger Transformer into a smaller Transformer, and researchers are actively exploring how far these ideas can transfer across model families.
The catch is that hidden representations often live in different spaces. The teacher may have wider layers, different head counts, or different recurrence patterns. A common solution is to add projection layers so that student features can be mapped into the teacher’s latent space before alignment losses are applied.
This is where KD stops being a purely conceptual trick and becomes engineering. Which layers do you align? How often? With what loss weight? Those choices meaningfully affect stability and student quality.
PyTorch Implementation: Feature-Based KD
The following code demonstrates how to engineer a custom KD loss that combines standard task loss, logit-matching (KL Divergence), and feature-based alignment using a learned projection layer.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ModernKDLoss(nn.Module):
def __init__(self, student_dim: int, teacher_dim: int, temp: float = 2.0, alpha: float = 0.5, beta: float = 0.1):
"""
Args:
student_dim: Hidden dimension of the student model.
teacher_dim: Hidden dimension of the teacher model.
temp: Temperature for logit smoothing.
alpha: Weight for the KL Divergence (Logit) loss.
beta: Weight for the Feature Alignment loss.
"""
super().__init__()
self.temp = temp
self.alpha = alpha
self.beta = beta
# Projection layer to bridge structural heterogeneity (e.g., 1024 -> 4096)
self.feature_projector = nn.Linear(student_dim, teacher_dim, bias=False)
self.kl_loss = nn.KLDivLoss(reduction="batchmean")
self.mse_loss = nn.MSELoss()
def forward(
self,
student_logits: torch.Tensor,
teacher_logits: torch.Tensor,
student_hidden: torch.Tensor,
teacher_hidden: torch.Tensor,
labels: torch.Tensor
) -> torch.Tensor:
# 1. Standard Task Loss (Cross Entropy)
task_loss = F.cross_entropy(student_logits, labels)
# 2. Logit-based KD Loss (KL Divergence)
# Scale by T^2 to maintain gradient magnitudes
soft_student = F.log_softmax(student_logits / self.temp, dim=-1)
soft_teacher = F.softmax(teacher_logits / self.temp, dim=-1)
kd_loss = self.kl_loss(soft_student, soft_teacher) * (self.temp ** 2)
# 3. Feature-based Alignment Loss
# Project student's hidden states to the teacher's latent space dimension
projected_student_hidden = self.feature_projector(student_hidden)
feature_loss = self.mse_loss(projected_student_hidden, teacher_hidden)
# Combine losses
total_loss = (1.0 - self.alpha) * task_loss + \
self.alpha * kd_loss + \
self.beta * feature_loss
return total_loss
# Example Execution
batch_size, seq_len, vocab_size = 4, 128, 32000
d_student, d_teacher = 1024, 4096
# Simulated Tensors
s_logits = torch.randn(batch_size * seq_len, vocab_size, requires_grad=True)
t_logits = torch.randn(batch_size * seq_len, vocab_size) # Teacher is frozen
s_hidden = torch.randn(batch_size, seq_len, d_student, requires_grad=True)
t_hidden = torch.randn(batch_size, seq_len, d_teacher) # Teacher is frozen
targets = torch.randint(0, vocab_size, (batch_size * seq_len,))
# Calculate Loss
criterion = ModernKDLoss(student_dim=d_student, teacher_dim=d_teacher)
loss = criterion(s_logits, t_logits, s_hidden, t_hidden, targets)
print(f"Total KD Loss: {loss.item():.4f}")
loss.backward() # Ready for optimizer step5. A Practical Distillation Playbook
If you are designing a distillation pipeline for a real product, the main questions are usually not philosophical. They are operational:
- What behavior matters most? Accuracy, latency, format adherence, tool use, or safety all imply different teacher signals.
- Is the teacher the right teacher? For specialized tasks, domain fit can matter more than raw parameter count.
- What failure modes do you evaluate? A student that looks good on clean benchmarks may still drift in length, calibration, or refusal behavior.
- Where is the budget spent? Teacher inference for rationale generation or on-policy scoring can dominate the total cost of the distillation pipeline.
This is why production distillation is rarely “train a small model on teacher outputs and stop.” It usually includes dataset curation, teacher quality checks, student-trajectory evaluation, and post-training release gates.
6. Interactive Component: Latent Space Alignment
To intuitively understand why Feature-Based KD often outperforms Logit-Only KD, interact with the visualizer below. It simulates how a student model’s internal representations map a problem space relative to a frozen teacher.
- Logit-Only KD: The student learns to imitate the final answer distribution, but its internal clustering can remain messy and brittle.
- Feature-Based KD: The student’s latent space shifts toward the teacher’s geometry, which often improves generalization and robustness.
7. Summary and Next Steps
Knowledge Distillation has grown from a simple logit-matching trick into a broader toolkit for transferring behavior from large models into smaller ones. The most effective pipelines now think carefully about teacher choice, divergence objectives, student-generated trajectories, and hidden-state alignment rather than treating KD as a single recipe.
Combined with quantization and sparsification, distillation is one of the most practical ways to make capable models deployable on tighter hardware and latency budgets. But smaller models still carry less knowledge internally. In Chapter 14: RAG (Retrieval Augmented Generation), we will see how retrieval can compensate for that limitation at inference time.
Quizzes
Quiz 1: In traditional Knowledge Distillation, what is the mathematical purpose of the Temperature () parameter applied to the Softmax function?
The Temperature parameter smooths out the probability distribution of the logits. A standard Softmax often produces a distribution heavily skewed towards a single class (e.g., [0.99, 0.005, 0.005]). By dividing logits by , the distribution flattens, amplifying the “dark knowledge” (the relative probabilities of incorrect answers) so the student can learn the teacher’s generalization patterns.
Quiz 2: Why can Reverse KL be appealing for autoregressive distillation compared with always using Forward KL?
Forward KL encourages broad coverage of the teacher distribution, which can be useful but may spread probability mass too widely for a smaller student. Reverse KL is more mode-seeking, so it can encourage the student to commit more strongly to the teacher’s preferred continuations. That can improve fluency in some generative settings, though it is not automatically the right choice for every task.
Quiz 3: What problem is On-Policy Distillation trying to solve?
It addresses the mismatch between clean teacher trajectories seen during training and the imperfect trajectories the student generates at inference time. By letting the teacher score sequences produced by the student itself, on-policy methods teach the student how to recover after its own mistakes instead of only showing ideal examples.
Quiz 4: Why are projection layers often introduced when distilling across different architectures?
Because teacher and student hidden states may live in spaces with different dimensions or geometry. A projection layer maps the student representation into a compatible space so that alignment losses such as MSE can be applied in a meaningful way.
Quiz 5: In a real distillation pipeline, why can teacher choice matter more than raw teacher size?
Because the student only learns from the signal the teacher provides. A domain-aligned teacher often produces cleaner outputs, more relevant rationales, and more useful hidden-state structure for the target task than a much larger but more general model. Bigger is not automatically better if the teacher’s behavior is mismatched to the deployment goal.
References
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- Hsieh, C. Y., et al. (2023). Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes. arXiv:2305.02301.
- Gu, Y., Dong, L., Wei, F., & Huang, M. (2024). MiniLLM: On-Policy Distillation of Large Language Models. arXiv:2306.08543.
- Agarwal, R., et al. (2024). On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes. arXiv:2306.13649.