15.2 Tree/Graph of Thoughts
The fundamental limitation of standard autoregressive generation—including standard Chain-of-Thought (CoT)—is its strict adherence to a Markovian, left-to-right decoding process. Once a token is sampled, it becomes an immutable part of the context window. If the model makes a logical error early in a complex reasoning chain, it is forced to condition all subsequent generation on that flawed premise.
Human cognition does not operate linearly when solving hard problems. We explore alternative hypotheses, hit dead ends, backtrack, and synthesize multiple partial solutions into a cohesive whole. To bridge this gap, researchers introduced search algorithms to LLM decoding, evolving the paradigm from linear chains to Trees, and ultimately, to Graphs of Thoughts.
1. The Tree of Thoughts (ToT) Framework
Introduced by Yao et al. (2023) [1], Tree of Thoughts (ToT) reframes LLM inference as a heuristic search problem over a combinatorial space of reasoning steps.
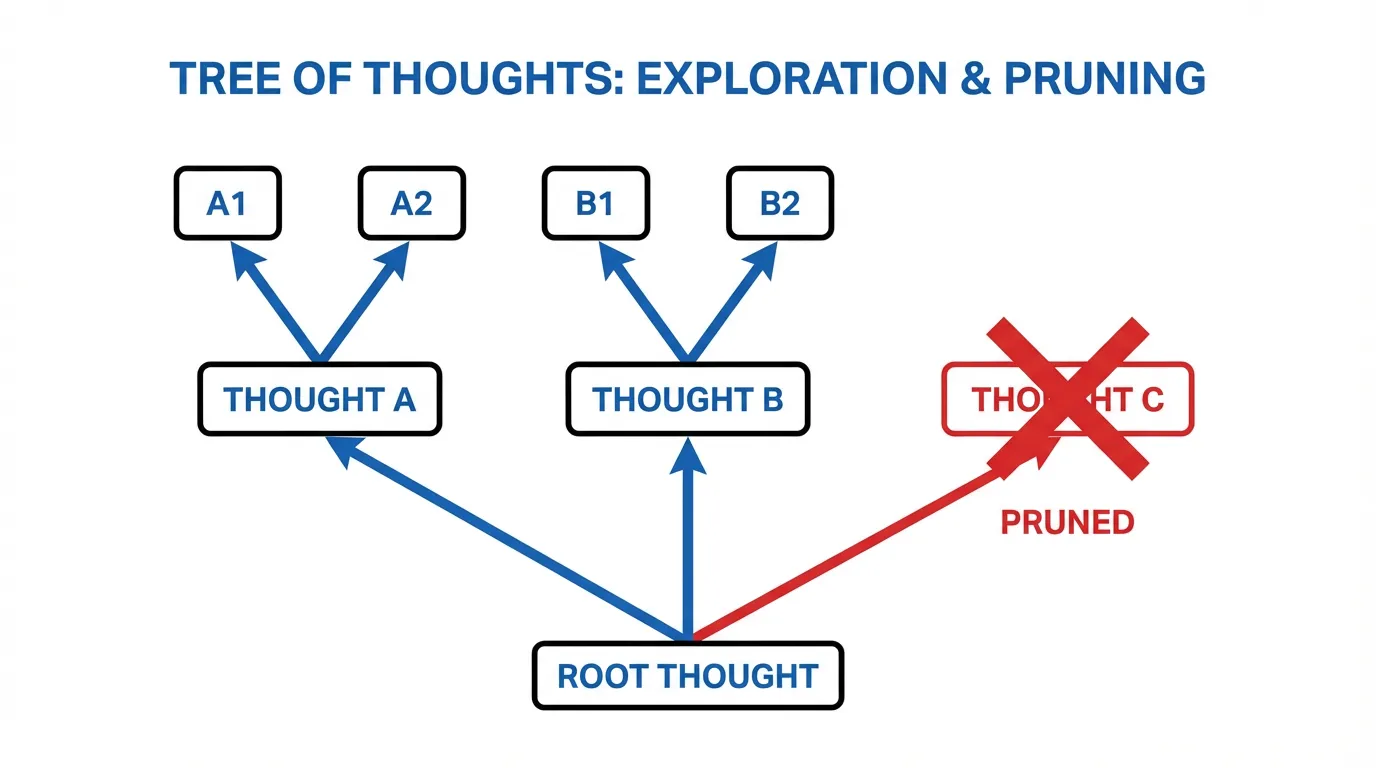
Instead of generating a single continuous sequence, ToT decomposes the problem into discrete “thoughts” (intermediate reasoning steps). The model explores multiple branches of thoughts, evaluating them to decide which paths to pursue and which to prune.
Mathematical Formulation
In standard CoT, we sample a sequence of thoughts to reach output given input . The probability is simply:
In ToT, we define a state representing a partial reasoning path. The framework requires two critical components:
- Thought Generator : Generates candidate next thoughts given the current state. This can be done via sampling (temperature ) or proposing distinct steps via a specific prompt.
- State Evaluator : A heuristic function that scores the viability of a state. The LLM itself is typically prompted to act as the evaluator, assigning a scalar value or a categorical label (e.g.,
sure,maybe,impossible).
With and defined, ToT applies classic search algorithms like Breadth-First Search (BFS) or Depth-First Search (DFS).
If using BFS with a beam width , at each depth , the algorithm keeps only the top states as ranked by . This prevents the exponential explosion of context while allowing the model to recover from localized errors by maintaining alternative branches.
2. Graph of Thoughts (GoT): Synergy and Recurrence
While ToT enables backtracking, it suffers from a structural flaw: Trees cannot merge. If two separate branches generate valuable, complementary partial solutions, ToT forces the system to choose one and discard the other.
Graph of Thoughts (GoT), proposed by Besta et al. (2023) [2], elevates the reasoning structure to a Directed Acyclic Graph (DAG). In GoT, vertices represent thoughts, and edges represent dependencies. This seemingly simple structural upgrade unlocks powerful cognitive operations that trees cannot support.
The Core Transformations
GoT introduces specific graph transformations modeled after human problem-solving:
- Aggregation (Synergy): Multiple thoughts are merged into a new thought . The LLM is prompted to synthesize the best elements of the parent thoughts. This is highly effective in tasks like document summarization or code synthesis.
- Refinement (Looping): A thought is iteratively improved to create . While technically creating a new node in the DAG to preserve acyclic properties, it acts as a self-correction loop.
- Generation: The standard ToT branching operation, creating new child thoughts from a parent.
The Cost-Quality Paradox
Intuitively, one might assume that GoT is vastly more expensive than ToT because it is more complex. However, GoT often achieves higher quality at a lower computational cost [2].
By identifying redundant or logically equivalent states across different branches and merging them (Aggregation), GoT prunes the search space more aggressively than ToT. In sorting tasks, GoT demonstrated a 62% increase in quality while reducing computational costs by over 31% compared to ToT.
When Tree or Graph Search Is Worth the Cost
ToT and GoT are not default decoding strategies for every prompt. They become attractive when all three of the following are true:
- the task has meaningful alternative solution paths
- partial progress can be evaluated or scored
- the cost of exploring extra branches is lower than the cost of committing early to a bad path
This is why they are a better fit for planning, constrained search, code repair, or synthesis tasks than for ordinary conversational turns. Search helps only when the problem actually has structure that can be searched.
3. Engineering the Orchestrator
Implementing GoT requires separating the system into a Controller (which manages the graph structure and search strategy) and an Executor (the LLM that generates and scores thoughts).
Below is a Python implementation demonstrating the core logic of a GoT Controller handling Generation and Aggregation.
import torch
from typing import List, Dict, Any
class GoTNode:
def __init__(self, thought: str, parents: List['GoTNode'] = None):
self.thought = thought
self.parents = parents or []
self.score = 0.0
self.children = []
class GoTController:
def __init__(self, llm_executor):
self.llm = llm_executor # Mock LLM interface
self.graph: List[GoTNode] = []
def generate_thoughts(self, node: GoTNode, k: int) -> List[GoTNode]:
"""Branches a node into k new thoughts."""
prompt = f"Given the current state: {node.thought}\nGenerate {k} distinct next steps."
responses = self.llm.generate(prompt, num_return_sequences=k)
new_nodes = [GoTNode(thought=r, parents=[node]) for r in responses]
node.children.extend(new_nodes)
self.graph.extend(new_nodes)
return new_nodes
def score_nodes(self, nodes: List[GoTNode]):
"""Evaluates nodes using the LLM as a heuristic function."""
for node in nodes:
prompt = f"Evaluate the validity of this reasoning step: {node.thought}. Score from 0.0 to 1.0."
score_str = self.llm.generate(prompt, max_tokens=5)[0]
node.score = float(score_str) # Simplified parsing
def aggregate_thoughts(self, nodes: List[GoTNode]) -> GoTNode:
"""Merges multiple synergistic nodes into a single superior node."""
combined_text = "\n".join([f"- {n.thought}" for n in nodes])
prompt = f"Synthesize the following partial solutions into one optimal solution:\n{combined_text}"
synergy_thought = self.llm.generate(prompt, max_tokens=256)[0]
synergy_node = GoTNode(thought=synergy_thought, parents=nodes)
for n in nodes:
n.children.append(synergy_node)
self.graph.append(synergy_node)
return synergy_node
def execute_search(self, initial_prompt: str):
# 1. Initialize Root
root = GoTNode(thought=initial_prompt)
self.graph.append(root)
# 2. Generate and Score (Branching)
candidates = self.generate_thoughts(root, k=3)
self.score_nodes(candidates)
# 3. Select top 2 for Aggregation (Synergy)
candidates.sort(key=lambda x: x.score, reverse=True)
top_candidates = candidates[:2]
# 4. Merge into final state
final_node = self.aggregate_thoughts(top_candidates)
return final_node.thoughtThe KV Cache Challenge
At the systems level, ToT and GoT introduce severe memory fragmentation. Every branch shares a common prefix (the root prompt and early thoughts), but diverges later.
If implemented naively, the KV cache for the shared prefix is duplicated in VRAM for every branch. Modern inference engines like vLLM utilize PagedAttention (discussed in Chapter 12) to share memory blocks across branches. When generating thoughts in parallel, the engine uses block-level copy-on-write mechanisms, ensuring that the memory footprint scales only with the divergent tokens, not the full context length of every branch.
4. State-of-the-Art: Adaptive Graph of Thoughts (AGoT)
The static nature of ToT and GoT means they apply the same heavy computational framework to every problem, regardless of difficulty.
Recent advancements, such as the Adaptive Graph of Thoughts (AGoT) [3], introduce Dynamic Decomposition. AGoT unifies CoT, ToT, and GoT by evaluating the complexity of the query at test-time.
- If the problem is simple, AGoT routes the query through a linear CoT path.
- If the model detects high uncertainty (often measured via entropy in the generation logits or self-reflection prompts), it dynamically expands the reasoning space into a graph.
This represents the frontier of Test-Time Scaling Laws. By allocating computation precisely where it is most needed, AGoT achieved a 46.2% improvement on the highly complex GPQA benchmark using standard inference models, matching the performance of models explicitly trained with heavy Reinforcement Learning (like OpenAI’s o1) but doing so entirely through inference-time orchestration.
5. Summary and Open Questions
The transition from Chains to Trees to Graphs represents a shift from treating LLMs as mere sequence predictors to utilizing them as engines within classical search architectures.
While GoT provides the structural capacity for human-like reasoning (synthesis and backtracking), it offloads the “thinking” policy entirely to external Python orchestrators. The next logical question—which we will explore in the next section on Search-time Compute and o1—is: Can we train the model to internalize this graph search, learning to branch, prune, and merge natively within its own hidden states?
Quizzes
Quiz 1: Why is Graph of Thoughts (GoT) often computationally cheaper than Tree of Thoughts (ToT) in tasks like sorting or set intersection, despite having a more complex DAG structure?
ToT forces an exponential expansion of branches. GoT allows for the “Aggregation” of states. By merging logically equivalent or redundant partial solutions from different branches into a single node, GoT drastically reduces the breadth of the search space, pruning redundant parallel computations.
Quiz 2: In a ToT implementation using Breadth-First Search (BFS) with beam width and depth , what is the primary systems-level bottleneck, and how do modern engines mitigate it?
The primary bottleneck is KV Cache memory explosion, which scales if not managed, as each branch maintains its own context. Modern engines mitigate this using PagedAttention (or RadixAttention), which allows multiple sequences to share the KV cache blocks of their common prefixes, only allocating new memory for the divergent generated tokens.
Quiz 3: How does the State Evaluator function in ToT differ fundamentally from a standard Reward Model used in RLHF?
A Reward Model in RLHF typically evaluates the final, complete output sequence to align with human preference. The State Evaluator in ToT evaluates partial, intermediate logical steps to serve as a heuristic for a search algorithm, determining if a current path is likely to lead to a correct final answer.
Quiz 4: What is the primary risk of the “Aggregation” transformation in GoT if the LLM’s synthesis capabilities are poorly calibrated?
Hallucination compounding. If the model merges two partially correct but logically contradictory thoughts, it may synthesize a corrupted state. Because this aggregated node serves as the foundation for future generation, the error propagates and pollutes the entire downstream graph.
Quiz 5: Explain the challenges of modeling state-space graph cycles when utilizing autoregressive Transformers, and how GoT frameworks circumvent this algorithmic limitation.
Autoregressive Transformers generate sequences linearly and are conditioned on a fixed context window where time is strictly forward-moving. This makes modeling graph cycles (revisiting a previous state) impossible natively, as appending a previous state simply extends the linear context length , incurring an attention cost without true cyclic graph logic. GoT frameworks circumvent this by utilizing an external Controller to handle cyclic operations (like refinement or looping). The Controller treats a loop as generating a new distinct node in the Directed Acyclic Graph (DAG) structure, preserving the causal attention mechanism while mimicking cyclic state refinement externally.
References
- Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601.
- Besta, M., et al. (2023). Graph of Thoughts: Solving Elaborate Problems with Large Language Models. arXiv:2308.09687.
- Pandey, T., Ghukasyan, A., Goktas, O., & Radha, S. K. (2025). Adaptive Graph of Thoughts: Test-Time Adaptive Reasoning Unifying Chain, Tree, and Graph Structures. arXiv:2502.05078.