17.3 Elo Rating & Leaderboards
Evaluating Large Language Models (LLMs) is one of the hardest problems in AI. Academic benchmarks like MMLU or GSM8K are static and prone to data contamination. To truly understand a model’s capabilities, the AI community has turned to human preference evaluation, formalized through Elo Rating systems and live Leaderboards.
The most prominent example of this is the LMSYS Chatbot Arena, where users chat with two anonymous models side-by-side and vote on which response is better. This crowdsourced, blind A/B testing creates a dynamic, hard-to-game leaderboard.
The Mechanism: Crowdsourced Duels
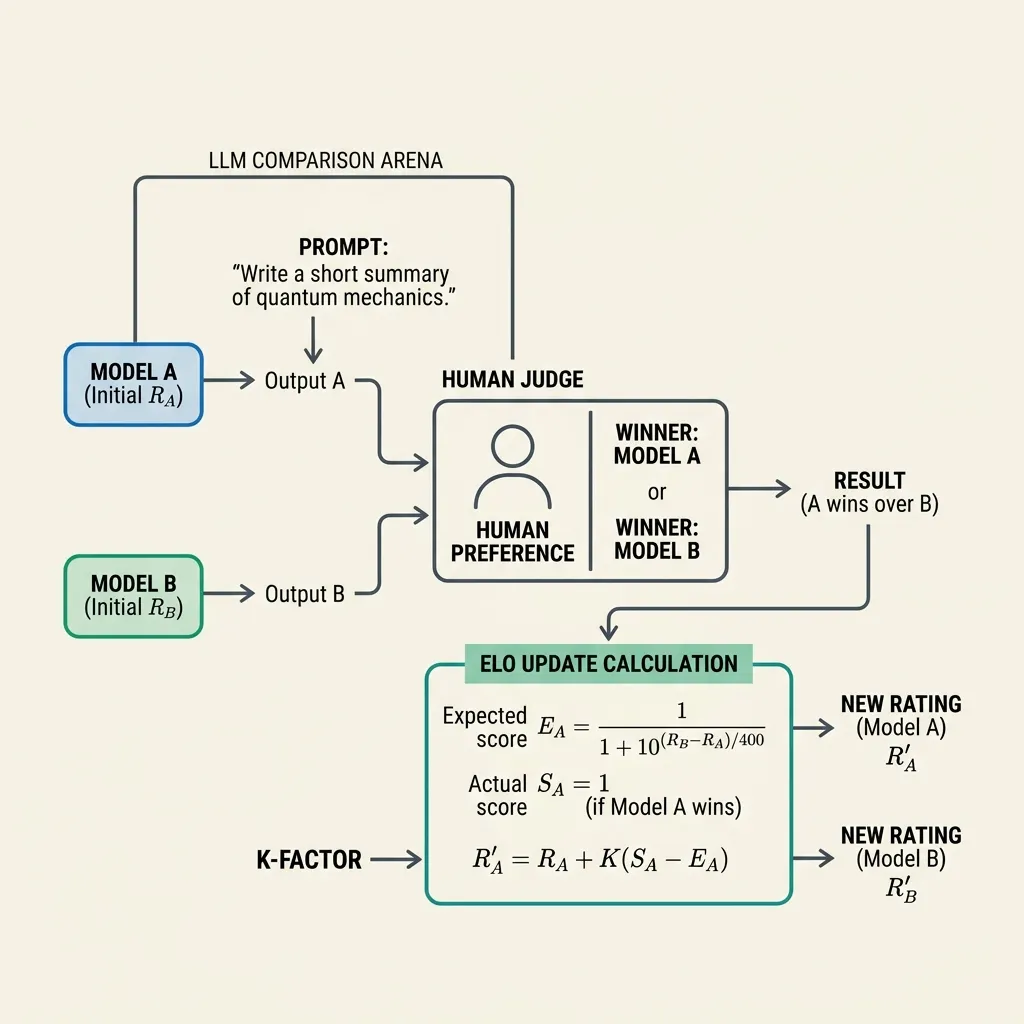
The process of building an LLM leaderboard using Elo ratings involves:
- Blind Duels: A user enters a prompt. Two anonymous models (e.g., Model A and Model B) generate responses.
- Human Judgment: The user votes for the better response (or declares a tie).
- Rating Update: The system updates the Elo ratings of both models based on the outcome and their pre-existing ratings.
 Source: Generated by Gemini
Source: Generated by Gemini
The Mathematics of Elo
Originally designed for chess, the Elo rating system calculates the relative skill levels of players. In the context of LLMs, the “players” are the models.
1. Expected Score
Given two models with ratings and , the expected score (probability of winning) for Model A is calculated using a logistic curve:
Similarly, for Model B:
Note that . If Model A has a rating points higher than Model B, , meaning Model A is expected to win of the time.
2. Rating Update
After a duel, the ratings are updated based on the actual score and the expected score :
Where:
- is the new rating.
- is a constant (K-factor) that determines how much a single game affects the rating (e.g., ).
- is the actual score: for a win, for a tie, and for a loss.
If a highly-rated model loses to a low-rated model, the rating change is large because is large.
Beyond Elo: The Bradley-Terry Model
While standard Elo updates ratings sequentially, platforms like LMSYS often use the Bradley-Terry model for offline analysis. The Bradley-Terry model fits a probability model to the entire dataset of duels at once using maximum likelihood estimation. It handles ties and multiple comparisons more robustly than sequential Elo updates.
Implementing Batch Elo Updates in PyTorch
For developers running internal model evaluations (e.g., comparing multiple fine-tuned versions), implementing a batch Elo update system in PyTorch can be highly efficient. Here is how to compute expected scores and updates for a batch of duels.
import torch
def compute_batch_elo_update(ratings_a, ratings_b, outcomes, k_factor=32.0):
"""
Compute Elo rating updates for a batch of duels.
Args:
ratings_a: Tensor of current ratings for Model A. Shape (batch_size,)
ratings_b: Tensor of current ratings for Model B. Shape (batch_size,)
outcomes: Tensor of outcomes for Model A (1.0 for win, 0.5 for tie, 0.0 for loss).
Shape (batch_size,)
k_factor: The K-factor hyperparameter.
Returns:
new_ratings_a: Updated ratings for Model A.
new_ratings_b: Updated ratings for Model B.
"""
# Compute expected scores
# We use torch.pow(10, ...) or exp with log(10)
exponent = (ratings_b - ratings_a) / 400.0
expected_a = 1.0 / (1.0 + torch.pow(10.0, exponent))
expected_b = 1.0 - expected_a
# Compute updates
# outcomes are scores for A. For B, score is (1.0 - outcomes)
update_a = k_factor * (outcomes - expected_a)
update_b = k_factor * ((1.0 - outcomes) - expected_b)
new_ratings_a = ratings_a + update_a
new_ratings_b = ratings_b + update_b
return new_ratings_a, new_ratings_b
# Example Usage
batch_size = 4
# Initial ratings
r_a = torch.tensor([1500.0, 1600.0, 1400.0, 1500.0])
r_b = torch.tensor([1400.0, 1700.0, 1400.0, 1500.0])
# Outcomes for A: Win, Loss, Tie, Win
outcomes = torch.tensor([1.0, 0.0, 0.5, 1.0])
new_a, new_b = compute_batch_elo_update(r_a, r_b, outcomes)
print("Original A:", r_a)
print("Updated A:", new_a)
print("Original B:", r_b)
print("Updated B:", new_b)Quizzes
Quiz 1: Why is a blind A/B test (like Chatbot Arena) considered superior to standard benchmarks for evaluating chat models?
Standard benchmarks are static and can be contaminated (included in training data), leading to inflated scores. A blind A/B test with human judges evaluates models on diverse, real-world prompts that are hard to predict or game. It measures actual user preference, which is the ultimate goal for chat assistants.
Quiz 2: What happens to the ratings if a model with 2000 Elo wins against a model with 1000 Elo? What if it loses?
If the 2000 Elo model wins, the rating change will be very small because the expected score was already close to 1.0. If it loses, the rating change will be very large (up to the full K-factor) because it was a highly unexpected result, causing the winner to gain many points and the loser to lose many.
Quiz 3: What is the main limitation of the sequential Elo update system compared to the Bradley-Terry model in evaluation platforms?
Sequential Elo updates are order-dependent; the final rating depends on the order in which games were processed. The Bradley-Terry model is a full-dataset optimization approach that considers all games simultaneously, making it more robust to the order of data and better at handling sparse data where not all models have played against each other.
Quiz 4: Derive the explicit optimization sequence logic when utilizing the Bradley-Terry model via Maximum Likelihood Estimation (MLE) for offline leaderboard updates.
The Bradley-Terry model defines the win probability as where is the continuous latent skill parameter. Offline calibration minimizes the aggregate negative log-likelihood . The gradient update for skill parameter is derived as: . Optimization applies sequentially until global calibration boundaries are converged, avoiding the order-dependent noise inherent in incremental Elo updates.
References
- Elo, A. E. (1978). The Rating of Chessplayers, Past and Present. Arco.
- Zheng, L., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685.