9.5 Synthetic Instructions & Self-Instruct
Consider a practical post-training scenario. A team is building a coding assistant for an internal framework. The base model can write acceptable Python, but it repeatedly misses the team’s style guide, safety rules, and domain-specific edge cases. Supervised Fine-Tuning (SFT) seems like the obvious solution, until the data requirement becomes clear: there are a few hundred reviewed examples, not tens of thousands of high-quality instruction-response pairs. That bottleneck is the real Data Wall.
This is one reason synthetic instruction generation has become central to modern post-training. Synthetic instruction pipelines let engineers use a strong teacher model to produce supervision that humans cannot economically write at scale: broader task coverage, more difficult reasoning traces, more failure cases, and greater domain variation. In many practical settings, the scarce resource is not GPU time but trustworthy labeled data.
In the previous section, we explored Prompt Engineering as a gradient-free alternative to Supervised Fine-Tuning (SFT). Here we look at the opposite scenario: what to do when explicit weight updates really are necessary, but fully human-written datasets are too expensive. This section follows the progression from Self-Instruct to Evol-Instruct and Magpie, then closes with the practical filters and guardrails teams use so synthetic data improves the model instead of poisoning it.
1. Practical Motivation
In practice, synthetic instruction pipelines help with three painful engineering problems:
- Coverage: they generate many phrasings, formats, and edge cases around the same task family.
- Difficulty shaping: they can start from simple seeds and mutate them into realistic debugging, planning, or multi-turn tickets.
- Reviewer leverage: they move human experts upward in the pipeline, from hand-writing every example to defining seeds, rubrics, filters, and spot checks.
From this perspective, synthetic data is not mainly about replacing humans. It is about allocating human review effort where it matters most: the long tail, policy-sensitive cases, and subtle failure patterns.
2. The Genesis: Self-Instruct
The concept of using a language model to generate its own training data was formalized in the seminal Self-Instruct framework by Wang et al. (2022) [1]. The core premise is iterative bootstrapping: an LLM pulls itself up by its own bootstraps by generating novel instructions, answering them, and filtering the results.
The Self-Instruct pipeline consists of four distinct phases:
- Instruction Generation: A small pool of human-written “seed” instructions (e.g., 175 tasks) is used as few-shot examples in a prompt to coax the model into generating entirely new instructions.
- Classification: The model determines whether the newly generated instruction represents a classification task (requiring a discrete label) or a generation task (requiring an open-ended response).
- Instance Generation: The model is prompted again to generate the actual input and output (the response) for the new instruction.
- Filtering: To prevent the model from collapsing into repetitive loops, new instructions are compared against the existing pool.
Mathematically, the filtering step uses a ROUGE-L overlap threshold to enforce diversity. An instruction is only added to the training pool if its maximum overlap with any existing instruction is below a threshold :
While revolutionary, vanilla Self-Instruct has a critical flaw: the generated instructions tend to plateau in complexity. The model naturally gravitates toward simple tasks (“Write a poem about a cat”, “Translate this sentence”), failing to generate the high-complexity reasoning tasks required to train state-of-the-art models.
3. Scaling Complexity: Evol-Instruct
To break past the complexity plateau, Xu et al. (2023) introduced Evol-Instruct, the engine behind the WizardLM model family [2]. Instead of merely asking the model to generate new instructions, Evol-Instruct forces the model to systematically upgrade existing instructions.
Evol-Instruct employs two distinct mutation strategies:
- In-depth Evolving: Increases the difficulty of the prompt by adding constraints, deepening the logic, requiring multi-step reasoning, or complicating the input format.
- In-breadth Evolving: Mutates the prompt into a completely different topic or domain to increase the dataset’s overall coverage.
By recursively applying the In-depth Evolver, a simple seed prompt like “Write a sorting algorithm” can be transformed over several epochs into a highly complex software engineering ticket.
Interactive Visualizer: The Evol-Instruct Process
Use the interactive component below to see how a base instruction is programmatically mutated through multiple levels of complexity using the Evol-Instruct methodology. Notice how the constraints force the model to utilize deeper reasoning pathways.
Evol-Instruct Progression
Click "Evolve" to mutate the prompt into a more complex instruction.
Base Instruction
Write a sorting algorithm.Analysis: A simple, generic request. The model will likely output a standard Bubble Sort or Quick Sort in Python without much thought.
4. Zero-Prompt Synthesis: Magpie
Both Self-Instruct and Evol-Instruct rely heavily on seed data and meta-prompts (e.g., “You are an instruction rewriting assistant…”). In 2024, the Magpie framework introduced a radically simpler approach: generating alignment data from scratch by prompting aligned LLMs with nothing [3].
Magpie exploits the auto-regressive nature of instruction-tuned models (like Llama-3-Instruct). During SFT, these models are trained on specific conversational templates. For example, a typical input looks like this:
<|user|>\n What is quantum mechanics? <|end|>\n <|assistant|>\n Quantum mechanics is...
Magpie bypasses the need for seed prompts entirely by simply feeding the model the pre-query template:
<|user|>\n
Because the model is fundamentally a next-token predictor, it is forced to complete the sequence. It hallucinates a plausible user query based on the latent distribution of its own SFT training data. Once the query is generated, it is fed back into the model to generate the assistant’s response. This zero-shot synthesis produces highly diverse, native-distribution instruction datasets without human intervention.
5. Engineering the Synthetic Pipeline
In frontier pipelines such as NVIDIA’s Nemotron-4 340B development, a very large share of the alignment data is synthetically generated. Nemotron-4 reports that more than 98% of the data used in its alignment process was synthetic [4]. This does not mean teams simply prompt a model and fine-tune on the output. It means they operate a multi-stage data pipeline with several quality gates.
Operating at this scale requires a robust pipeline. The most critical component is not the generator, but the Judge. Because LLMs hallucinate, generate toxic content, or write flawed code, a programmatic quality gate is mandatory. This is typically achieved using a Reward Model (RM) or an LLM-as-a-Judge to score the generated pairs.
Where is a reward model parameterized by , and is a strict quality threshold.
Additional Production Considerations
Production synthetic-data systems typically add several gates beyond the canonical research pipelines:
- Execution-based filters: for code, math, or tool-use tasks, passing tests is often a better filter than fluent prose alone.
- Cross-model separation: the generator, judge, and target student model are often kept distinct to reduce overfitting to one model family’s quirks.
- Distribution shaping: teams intentionally mix easy tasks, hard tasks, safety-sensitive cases, and domain-specific examples instead of letting the teacher sample only “average” prompts.
- Human spot checks: even highly automated pipelines still reserve manual review for policy drift, harmful outputs, and strange long-tail behaviors.
Below is a production-grade PyTorch implementation using vLLM to generate instructions via the Magpie method, followed by a strict filtering pass using a HuggingFace Reward Model.
import torch
from vllm import LLM, SamplingParams
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 1. Initialize the Generator (Teacher Model)
# We use vLLM for high-throughput batched generation
generator = LLM(model="meta-llama/Meta-Llama-3-70B-Instruct", tensor_parallel_size=4)
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=1024)
# 2. Initialize the Reward Model (Judge) for quality filtering
# In practice, models like Nemotron-4-340B-Reward or DeBERTa-v3 are used
rm_tokenizer = AutoTokenizer.from_pretrained("OpenAssistant/reward-model-deberta-v3-large")
reward_model = AutoModelForSequenceClassification.from_pretrained(
"OpenAssistant/reward-model-deberta-v3-large",
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 3. Magpie-style Instruction Generation
# We feed the model ONLY the user template. It auto-regressively hallucinates the query.
magpie_prompts = ["<|user|>\n"] * 1000
generated_queries = generator.generate(magpie_prompts, sampling_params)
# 4. Response Generation
full_conversations = []
for output in generated_queries:
user_query = output.outputs[0].text.strip()
# Format the hallucinated query into a full prompt to get the assistant's response
full_conversations.append(f"<|user|>\n{user_query}<|end|>\n<|assistant|>\n")
generated_responses = generator.generate(full_conversations, sampling_params)
# 5. Quality Filtering via Reward Model
high_quality_dataset = []
REWARD_THRESHOLD = 2.5 # Strict threshold to ensure SFT quality
with torch.no_grad():
for query, response in zip(generated_queries, generated_responses):
q_text = query.outputs[0].text.strip()
r_text = response.outputs[0].text.strip()
# Tokenize the full conversation for the Reward Model
inputs = rm_tokenizer(
f"<|user|>\n{q_text}<|end|>\n<|assistant|>\n{r_text}",
return_tensors="pt",
truncation=True
).to("cuda")
# Extract the scalar reward score
reward_score = reward_model(**inputs).logits.item()
# Only retain the synthetic data if it passes the quality gate
if reward_score >= REWARD_THRESHOLD:
high_quality_dataset.append({
"instruction": q_text,
"response": r_text,
"score": reward_score
})
print(f"Yield: {len(high_quality_dataset)} high-quality samples out of 1000.")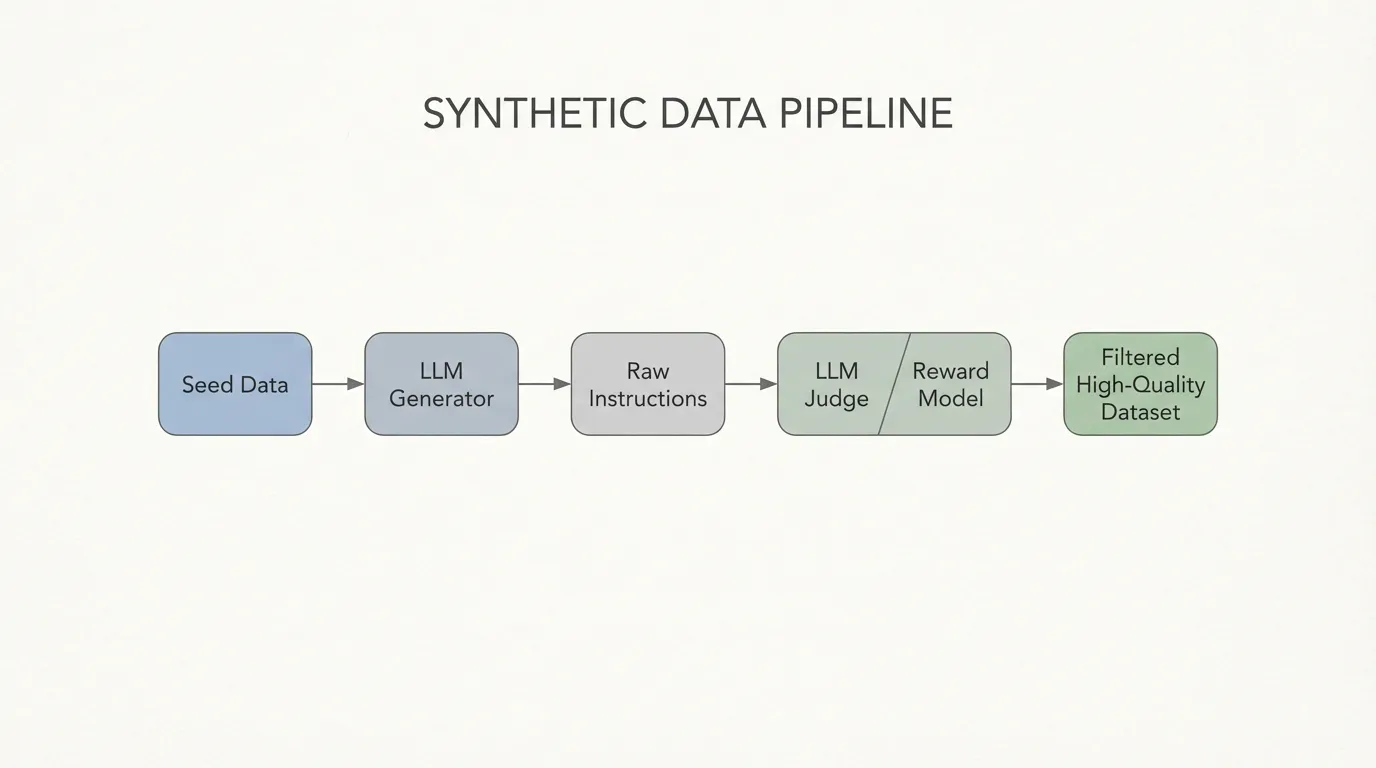 Source: Generated by Gemini. (Architecture of a modern synthetic data pipeline utilizing a Generator and a Reward Model filter).
Source: Generated by Gemini. (Architecture of a modern synthetic data pipeline utilizing a Generator and a Reward Model filter).
6. The Ouroboros Problem: Model Collapse
If synthetic data is so effective, why do we still need humans at all? The answer lies in the Curse of Recursion, commonly referred to as Model Collapse.
When an LLM generates data, it outputs a statistical approximation of the human data it was originally trained on. By nature, this approximation favors high-probability events (the “head” of the distribution) and smooths out low-probability events (the “tails”—such as edge cases, highly creative reasoning, and rare vocabulary).
If you train Model B entirely on data generated by Model A, and Model C on data from Model B, the tails of the distribution are progressively amputated. Over multiple generations, the model collapses into a state of extreme homogeneity, amplifying AI-specific stylistic artifacts (e.g., “As an AI language model…”, “Delve into…”) and losing its ability to generalize to novel human inputs.
To prevent model collapse, engineers must ensure Data Diversity by injecting human-curated seed data, employing aggressive diversity filtering (like the ROUGE-L metric in Self-Instruct), and utilizing temperature sampling during generation to artificially force the model into the tails of its distribution.
7. A Common Misuse: Synthetic Instructions Are Not a Substitute for Domain Adaptation
One of the easiest mistakes to make is to ask synthetic instruction data to do the job of missing pre-training knowledge. Supervised Fine-Tuning (SFT) focuses on teaching the model how to respond (format, persona, safety), but it is not designed to inject massive amounts of new, specialized knowledge. If you need a model to become an expert in a specific domain (e.g., legal analysis of Korean law, medical records in a specific hospital system, or a company’s internal codebase), standard SFT will often fail or hallucinate because the core knowledge was not acquired during the initial pre-training phase.
This is where Continued Pre-training (also known as Domain Adaptation or Incremental Pre-training) becomes critical for practitioners.
What is Continued Pre-training?
Continued Pre-training is the process of taking an already pre-trained base model (or even an instruction-tuned model) and continuing the self-supervised training process (next-token prediction) on a large corpus of domain-specific unlabeled text.
Continued Pre-training vs. SFT
| Feature | Continued Pre-training | Supervised Fine-Tuning (SFT) |
|---|---|---|
| Objective | Inject new domain knowledge / adapt vocabulary | Teach instruction-following and format |
| Data Type | Massive, unlabeled domain-specific text | Curated, labeled instruction-response pairs |
| Loss Function | Standard Autoregressive Cross-Entropy (all tokens) | Masked Cross-Entropy (response tokens only) |
| Compute Scale | High (requires substantial compute and data) | Low to Moderate |
| Risk | Catastrophic forgetting of general knowledge | Overfitting to specific prompt styles |
Real-World Implementation & Provider Services
In practice, many AI providers offer Continued Pre-training as a premium service because it requires significant engineering effort to prevent the model from forgetting its base capabilities.
- Enterprise Platforms: Companies like OpenAI, Anthropic, and Google often provide custom model training services where enterprises can upload massive datasets for continued pre-training in secure environments.
- Open Source Ecosystem: Platforms like Hugging Face and frameworks like
llama-factoryallow engineers to perform continued pre-training locally or on private clouds using techniques like LoRA (Parameter-Efficient) or full fine-tuning if compute permits.
For practitioners, the rule of thumb is: Use Continued Pre-training to teach the model what to know (domain knowledge), and use SFT to teach it how to act (interaction style).
8. Summary & Next Steps
The era of purely human-annotated SFT datasets is over. By leveraging frameworks like Self-Instruct, Evol-Instruct, and Magpie, engineers can distill the reasoning capabilities of massive frontier models into highly diverse, complex synthetic datasets. When paired with strict Reward Model filtering, these pipelines produce the high-fidelity data required to train the next generation of efficient, specialized models.
However, Supervised Fine-Tuning—whether on human or synthetic data—only teaches a model how to interact. It does not teach the model what humans actually prefer when multiple valid answers exist, nor does it inherently prevent the model from generating harmful content.
To bridge the gap between “following instructions” and “acting safely and beneficially,” we must move beyond imitation learning. In Chapter 10: Alignment: RLHF & Direct Preference, we will explore how models are mathematically aligned with complex human values using Reinforcement Learning and Preference Optimization.
Quizzes
Quiz 1: In Evol-Instruct, how is the expected number of reasoning tokens per successful generation step calculated?
If an instruction goes through steps of evolution, with each step having an expansion probability and an average of reasoning tokens per step, the expected total reasoning tokens is calculated as . For and constant , a step evolution requires an expected reasoning tokens.
Quiz 2: In the Magpie framework, how does providing only the
Magpie exploits the auto-regressive nature of already-aligned LLMs. Because the teacher model was trained to predict the next token across billions of conversational examples, feeding it the user-role token triggers its learned distribution of what a user typically asks. It effectively hallucinates a plausible user query without requiring any external prompt engineering.<|user|> template bypass the need for seed instructions?
Quiz 3: When engineering a synthetic data pipeline, why is a Reward Model (or LLM-as-a-Judge) a critical component after the generation phase?
While frontier models are excellent generators, they are prone to hallucinations, formatting errors, and generating toxic content. A Reward Model acts as a programmatic quality gate, evaluating the generated pair and assigning a scalar score. This allows engineers to systematically filter out low-quality data, ensuring the SFT dataset maintains a high signal-to-noise ratio.
Quiz 4: What is the primary mechanism behind “Model Collapse” when relying entirely on synthetic data across multiple model generations?
Model Collapse occurs because synthetic data is a statistical approximation of the original distribution that favors high-probability events. When models are recursively trained on model-generated data, the low-probability “tails” (edge cases, diverse reasoning paths) are lost. This leads to a compounding loss of diversity, amplified AI artifacts, and eventual degradation of generalized capabilities.
References
- Wang, Y., et al. (2022). Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560.
- Xu, C., et al. (2023). WizardLM: Empowering Large Language Models to Follow Complex Instructions. arXiv:2304.12244.
- Xu, Z., et al. (2024). Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing. arXiv:2406.08464.
- Adler, B., et al. (2024). Nemotron-4 340B Technical Report. arXiv:2406.11704.