11.3 Unified Multimodal (Any-to-Any)
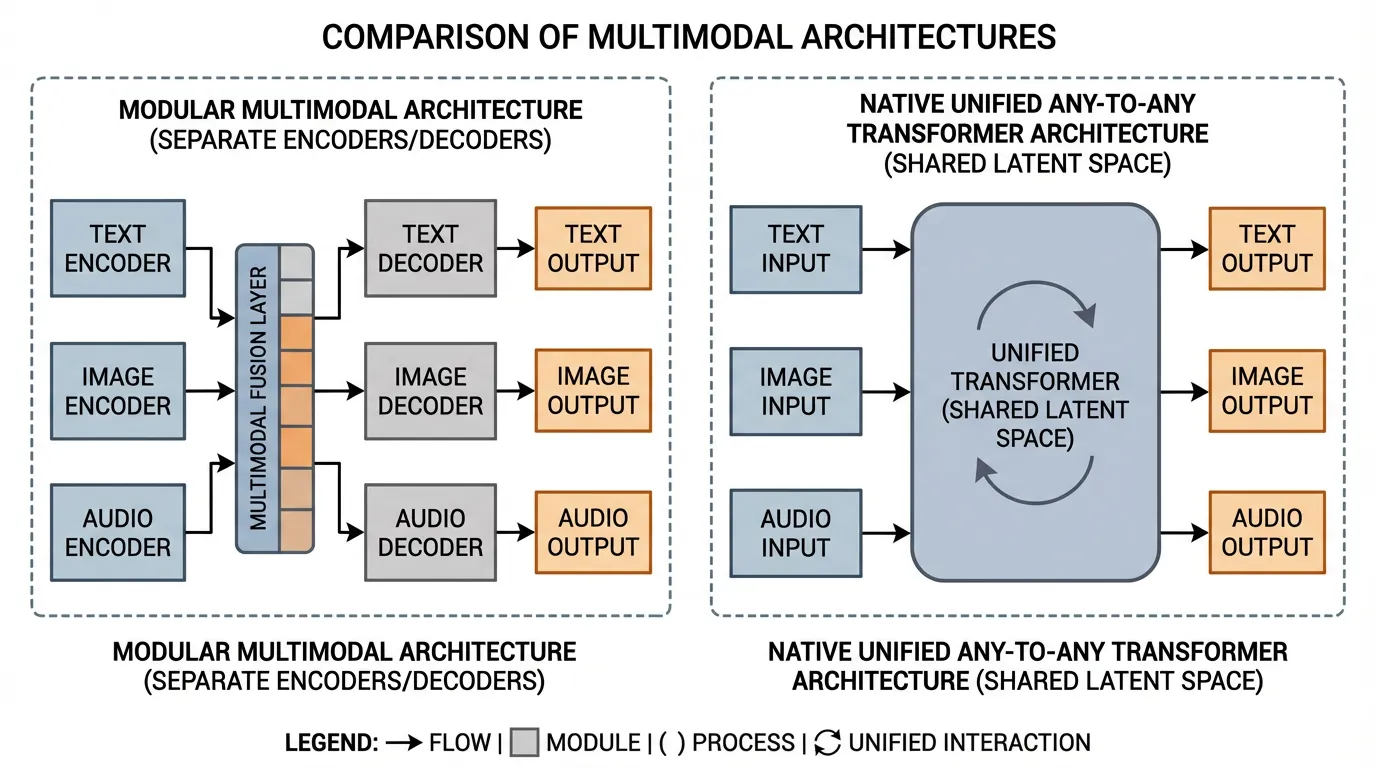
In the previous section, we explored how audio was integrated into Foundation Models, evolving from cascaded pipelines to continuous latent modeling. However, treating audio, vision, and text as isolated integration problems inevitably leads to system fragmentation. If a model requires a specialized adapter for images, a separate neural codec for audio, and a distinct diffusion head for video, the architecture becomes a fragile patchwork of glued-together components.
A visible research trend across 2024-2026 is the transition toward Native Any-to-Any Architectures. Instead of “modular multimodality”—where a pre-trained LLM is frozen and connected to external encoders via cross-attention—newer systems push more of the multimodal stack into a shared backbone. In that framing, text, image patches, audio frames, and sometimes action-like tokens are processed inside a common latent space.
This section dissects the engineering principles behind unified any-to-any models, exploring omni-tokenization, interleaved autoregression, and the modality-agnostic scaling laws that govern them.
 Source: Generated by Gemini.
Source: Generated by Gemini.
1. The Architecture of Unity: Omni-Tokens
The core engineering challenge of an Any-to-Any model is routing diverse, high-dimensional signals into a uniform Transformer backbone without destroying the unique characteristics of each modality.
In early multimodal models (e.g., Flamingo or early LLaVA), visual features were mapped into the text embedding space. The model essentially “translated” images into a text-like representation. In contrast, more native multimodal systems such as Qwen2.5-Omni [1], alongside product families like GPT-4o or Gemini, move closer to an Omni-Token Space design.
Instead of forcing modalities to mimic text, the model expands its base dimensionality to accommodate the intrinsic structures of all modalities. Text, continuous audio frames, and spatial image patches are projected into a shared high-dimensional space where they are treated as equal peers.
Interleaved Autoregression
Because all inputs share the same dimensional space, the Transformer can process them as a single, continuous sequence. This enables Fluid Context Switching. A user prompt can literally be structured as: [Text] [Image Patch] [Text] [Audio Frame]. The model computes self-attention across the entire interleaved sequence, allowing an audio token to directly attend to an image patch without routing through text.
Engineering the Omni-Projector
To achieve this, the input layer of the model is heavily modified. Instead of a single text embedding table, the model utilizes specialized, lightweight projectors for each modality that map raw features into the shared dimension .
Below is a realistic PyTorch implementation of an Omni-Token Projector. Notice the addition of learnable modality embeddings, which prevent the model from confusing a text token and an audio frame that happen to map to similar vectors in the shared space.
import torch
import torch.nn as nn
class OmniTokenProjector(nn.Module):
def __init__(self, hidden_dim=4096):
super().__init__()
self.hidden_dim = hidden_dim
# 1. Text embedding (standard discrete lookup)
self.text_embed = nn.Embedding(num_embeddings=128000, embedding_dim=hidden_dim)
# 2. Image patch projector (e.g., from ViT or SigLIP features)
self.image_projector = nn.Linear(1152, hidden_dim)
# 3. Audio frame projector (e.g., from a continuous audio encoder)
self.audio_projector = nn.Linear(1024, hidden_dim)
# Modality Type Embeddings (0: Text, 1: Image, 2: Audio)
# Crucial for helping the attention mechanism distinguish signal origins
self.modality_embed = nn.Embedding(num_embeddings=3, embedding_dim=hidden_dim)
def forward(self, text_ids=None, image_features=None, audio_features=None):
embeddings = []
if text_ids is not None:
text_emb = self.text_embed(text_ids)
# Add modality identifier
text_emb += self.modality_embed(torch.tensor(0, device=text_emb.device))
embeddings.append(text_emb)
if image_features is not None:
img_emb = self.image_projector(image_features)
img_emb += self.modality_embed(torch.tensor(1, device=img_emb.device))
embeddings.append(img_emb)
if audio_features is not None:
aud_emb = self.audio_projector(audio_features)
aud_emb += self.modality_embed(torch.tensor(2, device=aud_emb.device))
embeddings.append(aud_emb)
# In a real forward pass, tokens are interleaved based on sequence positions.
# For this demonstration, we concatenate them along the sequence dimension.
return torch.cat(embeddings, dim=1) if embeddings else None
# Example execution simulating an interleaved prompt
batch_size = 2
text_ids = torch.randint(0, 128000, (batch_size, 10)) # 10 text tokens
image_features = torch.randn(batch_size, 256, 1152) # 256 image patches (e.g., 16x16 grid)
audio_features = torch.randn(batch_size, 50, 1024) # 50 audio frames
projector = OmniTokenProjector(hidden_dim=4096)
unified_sequence = projector(text_ids, image_features, audio_features)
print(f"Text tokens shape: {text_ids.shape}")
print(f"Image patches shape: {image_features.shape}")
print(f"Audio frames shape: {audio_features.shape}")
print(f"Unified sequence shape: {unified_sequence.shape}")
# Output: -> 316 tokens perfectly aligned for the Transformer backboneInterleaved Autoregression (Causal Attention)
Hover over a token to see its attention weights to previous tokens across different modalities.
2. Tokenized Diffusion and Continuous Flow
While input projection is relatively straightforward, generating Any-to-Any outputs is historically complex. Text generation relies on next-token prediction over a discrete vocabulary via a Softmax layer. But how does an LLM generate a continuous 4K video or a high-fidelity audio waveform natively?
The VQ-VAE vs. DiT Debate
Until recently, the dominant approach was to force all outputs into discrete spaces using Vector Quantized Variational Autoencoders (VQ-VAE). The model would predict discrete “image tokens,” which a decoder would then render into pixels. However, as discussed in the previous section on audio, strict quantization introduces Discrete Representation Inconsistency (DRI), throwing away fine-grained continuous details.
One influential research direction resolves this by combining autoregressive reasoning with diffusion-style generation inside a unified stack [2].
Instead of a standard classification head (Softmax), the Transformer outputs continuous “omni-tokens” that act as structural blueprints. These continuous embeddings are fed directly into a lightweight Diffusion head (or DiT) appended to the end of the network.
- The autoregressive backbone handles the macro-structure, timing, and logical reasoning.
- The diffusion head handles the micro-structure, rendering the continuous physical details (pixels or waveforms).
This hybrid approach allows the model to maintain the logical rigor of next-token prediction while achieving the high-fidelity generation capabilities of continuous diffusion models.
3. Unified Scaling Laws and Cross-Modal Transfer
When models transition from unimodal to native Any-to-Any, their scaling behaviors change drastically. Research into Unified Scaling Laws [3] suggests that model performance is often driven by total compute across all modalities, evaluated using a generalized metric like Bits Per Character (BPC) or modality-normalized loss.
Cross-Modal Transfer Learning
The most profound engineering consequence of the Any-to-Any architecture is Cross-Modal Transfer Learning. Because all modalities share the same parameter weights in the attention layers, learning a concept in one modality mathematically improves the representation of that concept in others.
- Audio to Text: Training heavily on high-fidelity spatial audio improves the model’s ability to reason about physical space and timing in text-based physics word problems.
- Video to Physics: By predicting the next frame in a video stream while simultaneously processing the corresponding audio (e.g., a ball bouncing), the model internally learns a physics engine.
This phenomenon, sometimes referred to as “Emergent Synesthesia,” means that multimodal data is not just additive; it is multiplicative. You do not just get a model that can see and hear; you get a model that understands text better because it can see and hear.
4. Systems Engineering: Disaggregated Serving
Serving an Any-to-Any model in production introduces massive system bottlenecks. A single request might require text generation (memory-bound autoregression) followed immediately by video generation (compute-bound diffusion).
Frameworks like vLLM-Omni [4] address this via Disaggregated Serving. Instead of running the entire Any-to-Any pipeline on a single GPU cluster, the architecture is decomposed into a stage graph. The autoregressive LLM backbone runs on hardware optimized for KV-cache bandwidth, while diffusion-style heads are offloaded to compute-dense workers. The paper reports large job-completion-time gains from decoupling these stages rather than forcing one cluster to absorb every bottleneck.
Summary & Next Steps
The transition to Any-to-Any multimodality is not merely an interface update; it is a fundamental architectural rewrite. By mapping all sensory inputs into a shared Omni-Token space and utilizing continuous diffusion heads for generation, models bypass the lossy bottlenecks of modular adapters and discrete codecs. This unified approach unlocks cross-modal transfer learning, allowing models to build a more comprehensive, physics-grounded internal representation of reality.
Quizzes
Quiz 1: Why does mapping all modalities to a shared latent space (Omni-Tokens) reduce inference latency compared to modular architectures?
Modular architectures typically require cascading data through intermediate representations (e.g., converting audio to text, processing the text, then converting text to an image prompt). This creates sequential bottlenecks and requires loading multiple specialized models into memory. A shared latent space allows a single forward pass through one Transformer to process and generate all modalities simultaneously, drastically cutting latency and memory overhead.
Quiz 2: What is the primary advantage of integrating Tokenized Diffusion over strict discrete Vector Quantization (VQ) for generating continuous modalities like video?
Strict VQ forces continuous, high-dimensional data into a limited set of discrete token IDs, causing Discrete Representation Inconsistency (DRI) and discarding fine-grained details. Tokenized Diffusion allows the Transformer to output continuous embeddings that directly condition a diffusion head, preserving the high-fidelity micro-structures of physical signals (pixels/waveforms) while relying on the Transformer for macro-level logical planning.
Quiz 3: According to the Unified Scaling Law, how does cross-modal transfer learning affect a model’s capabilities?
Because all modalities share the same parameter weights in the attention layers, learning a concept in one modality improves its representation in others. For example, training on video and audio helps the model learn physical rules (like spatial relationships and timing), which mathematically improves its ability to reason about those same physical concepts when prompted in purely text-based tasks.
Quiz 4: In a production serving environment, why is Disaggregated Serving (like vLLM-Omni) necessary for Any-to-Any models?
Different modalities have conflicting hardware optimization requirements. Text generation (autoregression) is heavily memory-bandwidth bound due to the KV cache, while visual/audio generation (diffusion) is highly compute-bound. Disaggregated serving splits the model across different hardware clusters tailored to these specific bottlenecks, routing the intermediate omni-tokens between them to maximize total system throughput.
References
- Xu, J., et al. (2025). Qwen2.5-Omni Technical Report. arXiv:2503.20215.
- Xie, J., et al. (2024). Show-o: One Single Transformer to Unify Multimodal Understanding and Generation. arXiv:2408.12528.
- Sun, Q., & Guo, Z. (2024). Scaling Law Hypothesis for Multimodal Model. arXiv:2409.06754.
- Yin, P., et al. (2026). vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models. arXiv:2602.02204.